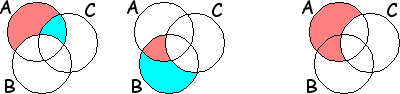In science, one tries to tell people something that no one ever
knew before, in such a way as to be understood by everyone.
But in poetry, it's the exact opposite. Paul A.M. Dirac (1902-1984;
Nobel 1933)
(2002-11-01) The Quantum Substitute for Logic
How is the probability of an outcome computed in quantum theory?
If you're not completely confused by
quantum mechanics,
you do not understand it.
John Archibald Wheeler
(1911-2008)
First, let's consider how probabilities are ordinarily
computed:
When an event consists of two mutually exclusive events,
its probability is the sum of the probabilities of those two events.
Similarly, when an event is the conjunction
of two statistically independent events,
its probability is the product of the probabilities of those two events.
For example, if you roll a fair die,
the probability of obtaining a multiple of 3 is
1/3 = 1/6+1/6; it's the sum of the probabilities (1/6 each)
of the two mutually exclusive events "3" and "6".
You add probabilities when the
component events can't happen together (the outcome of the roll cannot be
both "3" and "6").
On the other hand, the probability of rolling two fair dice without obtaining a 6
is 25/36 = (5/6)(5/6); it's the product of the probabilities
(5/6 each) of two independent events,
each consisting of not rolling a 6 with each throw.
Quantum Logic and [Complex] Probability Amplitudes :
In the quantum realm, as long as two logical possibilities are not actually observed,
they can be neither exclusive nor independent
and the above does not apply.
Instead, quantum mechanical probability amplitudes are defined as
complex numbers whose
absolute values squared correspond to ordinary probabilities.
The phases (the angular directions) of such complex numbers
have no classical equivalents
(although they happen to provide a deep explanation for the existence
of the conserved classical quantity known as electric charge).
To obtain the amplitude of an event with two
unobserved logical components:
For EITHER-OR (exclusive) components,
the amplitudes are added.
For AND (independent) components,
the amplitudes are multiplied.
In practice, "AND components" are successive steps that
could logically lead to the desired
outcome, forming what's called an acceptable history for that outcome.
The "EITHER-OR components", whose amplitudes are to be added,
are thus all the possible histories logically leading up to the same outcome.
Following Richard Feynman,
the whole thing is therefore called a "sum over histories".
These algebraic manipulations are a mind-boggling substitute for statistical logic,
but that's the way the physical universe appears to work.
The above quantum logic normally applies only at the microscopic level,
where "observation" of individual components is either impossible or would
introduce an unacceptable disturbance.
At the macroscopic level, the observation of a combined outcome usually implies that
all relevant components are somehow "observed" as well (and the ordinary
algebra of probabilities applies).
For example, in our examples involving dice, you cannot tell
if the outcome of a throw is a multiple of 3 unless you actually observe
the precise outcome and will thus know if it's a "3" or a "6",
or something else.
Similarly, to know that you haven't obtained a "6"
in a double throw, you must observe separately the outcome of each throw.
Surprisingly enough, when the logical components of an event are only imperfectly
observed (with some remaining uncertainty), the probability of the outcome
is somewhere between what the quantum rules say
and what the classical rules would predict.
(2007-07-19) On the "Statistics" of Elementary Particles
A direct consequence of quantum logic:
Pauli's Exclusion Principle
In very general terms, you may call "particle" some part of a quantum
system. Swapping (or switching) a pair of particles is making one
particle take the place of the other and vice versa, while leaving everything else
unchanged.
Although swapping particles may deeply affect a quantum system,
swapping twice will certainly not change anything since, by definition,
this is like doing nothing at all.
"Swapping" can be defined as something that does nothing
if you do it twice.
Particles are defined to be "identical" if they can be swapped.
So, according to the abovequantum logic,
the amplitude associated with one swapping
must have a square of 1.
Therefore (assuming that amplitudes are ordinary
complex numbers) the swapping amplitude is
either +1 or -1.
In the mathematical description of quantum states, swapping
is well-defined only for particles of
the same "nature". Whether swapping involves a multiplicative factor of
+1 or -1 depends on that "nature".
Particles for which swapping leaves the quantum state unchanged are called
bosons, those for which swapping negates the quantum state are called
fermions.
A deep consequence of Special
relativity is that spin
determines which "statistics" a given type of particles obeys
(Bose-Einstein statistics
for bosons, Fermi-Dirac statistics for fermions).
Part of the angular momentum of a fermion can't be explained in classical terms
(it must include a nonorbital "pointlike" component).
The spin of a boson is a whole multiple of the quantum
of angular momentum
h/2p, whereas the spin of a fermion is
an odd multiple of the "half quantum" h/4p.
With the concepts so defined, let's consider a quantum state where two
fermions would be absolutely indistinguishable.
Not only would they be particles of the same kind (e.g., two electrons)
but they would have the same position, the same state of motion, etc.
So, the quantum state is clearly unchanged by swapping.
Yet, swapping fermions must negate the quantum state...
Therefore, it's equal to its own opposite and can only be zero !
The probability associated to a zero quantum state is zero;following
this corresponds to something impossible. In other words,
two different fermions can't "occupy" the exact same state.
This result is called Pauli's exclusion principle.
It's the reason why all the electrons around a nucleus don't collapse
to the single state of lowest energy.
Instead, they occupy successively different "orbitals", according to rules
which explain the entire periodic table of
chemical elements.
(2002-11-01) The Infamous Measurement Problem
What does a quantum observation entail?
There are no things, only processes.
David Bohm (1917-1992)
That's the most fundamental unsolved question in quantum mechanics.
According to the above, one should deal strictly
with amplitudes between observations (or measurements),
but another recipe holds when measurements are made (according to the
Copenhagen interpretation).
Whatever a measurement entails
(which nobody has precisely defined yet)
it includes at the very least a distinction between the observer
and the observed and a transfer of information
from the latter to the former.
Nothing prevents us from considering a larger system which includes both the
observer and the observed (possibly the whole Universe) where no
such information leak takes place.
The state of that larger system obeys the unaltered Schrödinger equation
(or any relevant generalization thereof) whose unitarity
actually expresses the conservation of information.
(The classical counterpart of that is
Liouville's theorem.)
For a system which isn't measured by any outside agency,
it's thus difficult to avoid the conclusion that a large enough system can
observe itself, in some obscure sense.
Information gets concentrated at some locations and depleted at others.
Either way, the simple quantum rules outlined above would have to be smoothly modified
to account for a behavior which can be nearly classical for a large enough system.
In other words, the above quantum ideas
(which constitute the Copenhagen interpretation)
must be incomplete, because they fail to describe
any bridge between a quantum system waiting only to be observed,
and an entity capable of observation.
Our current quantum description of the world has proven its worth and reigns supreme,
just like Newtonian mechanics reigned supreme
before the advent of Relativity Theory.
Relativity consistently bridged the gap between the slow and the fast,
the massive and the massless (while retaining the full applicability of
Newtonian theories to the domain of ordinary speeds).
Likewise, the gap must ultimately be bridged between observer and observed,
between the large and the small,
between the classical world and the quantum realm,
for there is but one single physical reality in which everything is immersed...
This bothers, or should bother, everybody who deals with quantum mechanics:
The so-called Schrödinger's Cat theme is often used to discuss the
problem, in the guise of a system that includes a cat (a "qualified" observer)
in the presence of a quantum device which could trigger a lethal device.
It seems silly to view the whole thing as a single quantum system,
which would only exist (until observed) in some
superposition of states, where the cat would
be neither dead nor alive, but both at once.
Something must exist which collapses the quantum state of
a large enough system frequently enough to make it appear "classical".
It stands to reason that Schrödinger's Cat must be dead
very shortly after being killed... Doesn't it?
Otherwise, we're led to the bizarre conclusion that several
versions of reality can somehow co-exist indefinitely.
That's a respectable viewpoint, which was introduced in 1957 by
Hugh Everett (1930-1982)
and is now known as Everett's many-worlds interpretation.
(2005-07-03) Matrix Mechanics (Heisenberg, 1925)
Physical quantities are multiplied like matrices... Order matters.
In June 1925, Werner Heisenberg
(1901-1976; Nobel 1932)
discovered that observable physical quantities
obey noncommutative rules similar to those governing
the multiplication of algebraic matrices.
If the measurement of a physical quantity would disturb the measurement of the
other, then a noncommutative circumstance exists which disallows even the
possibility of two separate sets of experiments yielding
the values of these two quantities with arbitrary precision (read this again).
This delicate connection between
noncommutativity and uncertainty
is now known as Heisenberg's uncertainty principle.
In particular, the position and momentum of a particle can only be measured with respective
uncertainties
(i.e., standard deviations in repeated experiments)
Dx and
Dpx satisfying the following inequality :
The early development of Heisenberg's Matrix Mechanics
was undertaken by M. Born and P. Jordan.
In March 1926, Erwin Schrödinger
showed that Heisenberg's viewpoint was equivalent to his own undulatory approach
(Wave Mechanics, January 1926) for which he would share the 1933 Nobel prize with
Paul Dirac, who gave basic Quantum Theory
its current form.
Heisenberg's picture [ skip on first reading ] :
Here is a terse summary of Heisenberg's original viewpoint
in terms of the Schrödinger picture which we adopt
elsewhere on this page, following Paul Dirac
and almost all modern scholars:
In the modern nonrelativistic Schrödinger-Dirac picture, a
ket |y> is
introduced which describes a quantum state varying with time.
Since it remains of unit length, its value at time t is obtained from its value at time
0 via a unitary operator Û.
| yt >
=
Û (t,0)
| y0 >
The unitary operator Û so defined is called the
evolution operator.
Heisenberg's picture consists in considering that a given system is represented
by the constant ket
Û* |y>.
Operators are modified accordingly...
A physical quantity which is associated with the operator Â
in the Schrödinger picture
(possibly constant with time) is then associated with the following
time-dependent operator in the Heisenberg picture.
(2002-11-02) The Schrödinger Equation (1926)
The dance of a single nonrelativistic particle in a classical force field.
The Schrödinger equation governs the
probability amplitude y
of a particle of mass m and energy E
in a space-dependent potential energy V.
Strictly speaking, E is the total relativistic
mechanical energy
(starting at mc2 for the particle at rest).
However, the final stationary Schrödinger equation
(below) features only the
difference E-V with respect to the potential V,
which may thus be shifted to incorporate the rest energy
of a single particle.
For several particles, the issue cannot be skirted so easily
(in fact, it's partially unresolved) and it's one of several reasons
why the quantum study of multiple particles takes the form of an
inherently relativistic theory
(Quantum Field Theory)
which also accounts for the creation and annihilation of particles.
In 1926, when the Austrian physicist
Erwin Schrödinger
(1887-1961; Nobel 1933)
worked out the equation now named after him, he thought that the relevant quantity
y
was something like a density of electric charge...
Instead, y
is now understood to be a probability amplitude, as
defined in the above article,
namely a complex number whose squared length is proportional to the probability
of actually finding the electron at a particular position in space.
That interpretation of y was proposed by
Max Born
(1882-1970; Nobel 1954)
the very person who actually coined the term quantum mechanics
(Max Born also happens to be the maternal grandfather of
Olivia Newton-John).
The controversy about the meaning of y hindered neither
the early development of Schrödinger's theory of "Wave Mechanics",
nor the derivation of the nonrelativistic equation at its core:
A Derivation of Schrödinger's Equation :
We may start with the expression of the phase-speed, or celerity
u = E/p of a matter wave, which comes directly from
de Broglie's principle,
or less directly from other
more complicated analogies
between particles and waves.
The nonrelativistic (defining) relations
E = V + ½ mv 2 and
p = mv imply:
p = Ö
2m (E-V)
Therefore, the wave celerity u = E/p is simply:
u = E / Ö
2m (E-V)
Now, the general 3-dimensional wave equation
of some quantity j propagating
at celerity u is:
1
¶ 2 j
=
¶ 2 j
+
¶ 2 j
+
¶ 2 j
u 2
¶ t 2
¶ x 2
¶ y 2
¶ z 2
=
Dj
[D is the Laplacian operator]
The standard way to solve this (mathematically)
is to first obtain solutions j which are
products of a time-independent space function y
by a sinusoidal function of the time (t) alone.
The general solution is simply a linear superposition of these
stationary waves :
j =
y exp (
-2pin t )
For a frequency n, the stationary amplitude
y thus defined must satisfy:
Dy +
( 4pn2 / u2 )
y = 0
Using n = E/h
(Planck's formula) and the above for
u = E/p we obtain...
The Schrödinger Equation :
Schrödinger's Stationary Equation
Dy +
(8 p2 m / h2 )
(E - V) y
= 0
This equation is best kept in its nonrelativistic context,
where it determines allowed levels of
energy up to an additive constant.
A frequency may only be associated with a Schrödinger solution
at energy E if E is the total relativistic energy (including rest energy)
and V has been adjusted accordingly, against the usual nonrelativistic freedom,
as discussed in this article's introduction.
In the above particular stationary case, we have:
E j
=
( i h / 2p )
¶j/¶t
This relation turns the previous equation into
a more general linear equation :
Schrödinger's Wave Equation
( i h / 2p ) ¶j/¶t
=
V j -
( h2 / 8p2 m )
Dj
Signed Energy and the Arrow of Time
Historically, Erwin Schrödinger associated an equally valid
stationary function with the positive (relativistic) energy
E = hn and obtained a
different equation :
j =
y
exp (2pin t )
( -i h / 2p ) ¶j/¶t
=
V j -
( h2 / 8p2 m )
Dj
Formally, a reversal of the direction of time turns one equation into the other.
We may also allow negative energies and/or frequencies in
Planck's formula E = hn
and observe that a particle may be described by the same wave function
whether it carries energy E in one direction of time, or energy
-E in the other.
To retain only one version of the Schrödinger equation and
one arrow of time (the term was coined by Eddington)
we must formally allow particles to carry a signed energy
(typically, E = ± mc2 ).
If the wave function j
is a solution of one version of the Schrödinger equation, then its
conjugate j* is a solution of the other.
However, time-reversal and conjugation need not result in the same wave
function whenever Schrödinger's equation has
more than one solution at a given energy.
Principle of Superposition :
The linearity of Schrödinger's equation means that
any sum of satisfactory solutions is also a solution.
This
principle of superposition justifies the
general Hilbert space formalism introduced by Dirac:
Until it is actually measured,
a quantum state may contain (as a linear superposition)
several acceptable realities at once.
This is, of course, mind-boggling.
Schrödinger and many others have argued that
this cannot beentirely true:
Something in the ultimate quantum rules must
escape any linear description to defeat this
principle of superposition, which is unacceptable
as an overall rule for everything observed and anything
observing.
The standard vocabulary for the Hilbert spaces used in quantum mechanics
started out as a pun:
P.A.M. Dirac (1902-1984;
Nobel 1933)
decided to call < j | a bra
and | y > a ket,
because
< j | y >
is clearly a bracket...
Hilbert Space and "Hilbertian Basis" :
A Hilbert space
is a vector space over the field of
complex numbers
(its elements are called kets ) endowed with an
inner hermitian
product (Dirac's "bracket", of which the left half is a "bra").
That's to say that the following properties hold
(z* being the complex conjugate of z):
Hermitian symmetry:
< y | j >
=
< j | y >*
is a complexscalar.
Semilinearity:
< j | (
x | x > + y | y >)
=
x < j | x > +
y < j | y >
For any nonzero ket | y >,
the real < y | y >
is positive
(= ||y|| 2 ).
A Hilbert space is also required to be
separable and
complete,
which implies that its dimension is either finite or countably infinite.
It's customary to use raw indices for the kets of an agreed-upon
Hilbertian basis :
| 1 >, | 2 >, | 3 >, | 4 > ...
Such a "basis" is a maximal
set of unit kets which are pairwise orthogonal :
< i | i > = 1 and < i | j > = 0
if i ¹ j
The so-called closure relationÎ = å
| n > < n |
is a nice way to state that any ket is a
generalized linear combination of kets from the "basis":
| y >
=
Î | y >
=
å
| n > < n | y >
=
å
< n | y > | n >
This need not be a proper linear combination,
since infinitely many of the coefficients
< n | y >
could be nonzero: An
Hilbertian basis is not a properlinear basis unless it's finite
(cf. Hamel basis).
Operators :
A linear operator is a
square matrix = [ a ij ]
which we may express as:
 = å
a ij | i > < j |
alternately,
a ij =
< i | Â | j >
To the left of a ket or the right of a
bra, Â yields another like vector.
Hermitian conjugation generalizes to vectors and operators the
complex conjugation of scalars.
We prefer to use the same notation X* for the hermitian conjugate
of any object X, regardless of its dimension.
We use interchangeably the terms which other authors prefer to
use for specific dimensions, namely conjugate for scalars,
dual for vectors (bras and kets) and adjoint for operators
(the adjugate of a matrix is something
entirely different).
A operator equal to its own Hermitian conjugate is said to be
self-adjoint or Hermitian (French: auto-adjoint).
Many authors (especially in quantum theory)
use an overbar for the conjugate of a scalar and an obelisk
("dagger") for the adjointA
of an operator A.
In other words,
A º A*
Loosely speaking, conjugation consists in replacing all coordinates by
their complex conjugates and
transposing (i.e., flipping about the main diagonal).
The conjugate transpose is also called adjoint, Hermitian adjoint,
Hermitian transpose, Hermitian conjugate, etc.
The word conjugate can also be used by itself,
since conjugation of the complex coordinates
of a vector or matrix is rarely used, if ever, without a simultaneous transposition.
| y >* = < y |
and
< y |* = | y >
< j | Â* | y >
=
( < y | Â | j > )*
The adjoint of a product is the product of the adjoints in reverse order.
For an inner product, this restates
the axiomatic hermitian symmetry.
( X Y )* = Y* X*
< y | j >*
=
< j | y >
An operator  is self-adjoint or
hermitian if  = Â*.
All eigenvalues of an hermitian operator are real.
That key theorem was established in 1855 by Charles
Hermite (1822-1901, X1842)
when he introduced the relevant concepts now named after him:
hermitian conjugation, hermitian symmetry, etc.
Two eigenvectors of an hermitian operator
for distinct eigenvalues are necessarily orthogonal
(see proof below).
In finitely many dimensions, such operators are diagonalizable.
An hermitian operator multiplied by a real
scalar is hermitian.
So is a sum of hermitian operators,
or the product of two commuting hermitian operators.
The following combinations of two hermitian operators are always hermitian:
1/2
( Â Ê + Ê Â )
1/2i
( Â Ê - Ê Â )
The first operation is a commutative product which
endows the Hermitian operators with the structure of a
Jordan algebra
(it's not an associative algebra but
it's a power-associative one).
Unitary Transformations Preserve Length :
A unitary
operator Û is a Hilbert isomorphism:
Û Û* = Û* Û = Î.
It transforms an
Hilbertian basis
into another Hilbertian basis and turns
| y >,
< j | and
 respectively into
Û | y >,
< j | Û* and
ÛÂÛ*.
For an infinitesimal e,
Û = Î + ieÊ
is unitary (only) when Ê is hermitian.
State Vectors, Observables and the Measurement Postulate :
A quantum state, state vector, or microstate is a ket
| y > of unit length :
< y | y >
= 1
Such a ket | y >
is associated with the density operator
| y >
< y |
(whose entropy is zero) which determines it back,
within some physically irrelevant phase factor exp(iq).
An observable physical quantity corresponds to an hermitian
operator  whose eigenvalues are the possible values of a
measurement.
The average value of a measurement of
 from a pure microstate
| y > is:
< y | Â | y >
This is a corollary of the following measurement postulate
(von Neumann's projection postulate)
which states the consequence of a measurement,
in terms of the eigenspace projector matching each possible outcome
Any outcome a is necessarily an eigenvalue
of = åa
a
Pa
| y > becomes
Pa
| y >
|| Pa
| y > ||
with probability < y |
Pa | y >
The above is also often called the
principle of spectral decomposition.
Note that, since P2 = P = P*,
we have:
|| P | y > || 2
=
< y | P | y >
Vocabulary:
The principle of quantization limits the observed
values of a physical quantity to the eigenvalues of
its associated operator.
The principle of superposition
asserts that a pure quantum state is represented by a ket...
A quantum state represented by an eigenvector of an observable
is called an eigenstate. It always
yields the same measurement of that observable.
Orthogonality of Eigenspaces :
Two kets |y> and
|j> that are eigenstates of an hermitian
operator  associated with
distinct
eigenvalues a and
b are necessarily orthogonal.
Proof : If
 |y> = a |y>
and
<j| Â =
b <j| with
a ¹ b, then we have:
<j| Â |y> = a <j|y> = b <j|y>.
Therefore, <j|y> = 0
(2020-10-04) Hilbert space for a composite system.
It's a tensor product of Hilbert spaces
(not a direct product).
The Hilbertian basis for the composite space is indexed by two independent
sets of labels inherited from labels which would denote the two parts.
| i > Ä | j > = | i, j >
The "factors" on the left-hand-side are purely hypothetical, since the parts of a quantum system
can't be considered separately, a priori.
In the finite-dimensional case where we have m labels for the
first part and n labels for the second one, we have
m×n labels for the composite space
(as opposed to the m+n labels we'd have for an irrelevant direct product).
(2005-07-03) Commutators.
Lie Algebra of Quantum Operators.
The commutator of two operators
A and B is :
[A,B] = AB - BA.
Algebraic Rules for Commutators :
A few general relations hold about commutators, which are easily verified :
[B,A]
=
- [A,B] (anticommutativity)
[A,B]*
=
[B*, A*]
[A,B+C]
=
[A,B] + [A,C]
[A,BC]
=
[A,B]C + B[A,C]
Ô
=
[A,[B,C]] +
[B,[C,A]] +
[C,[A,B]]
This last relation is known as the Jacobi identity.
It's the relations an anticommutative bilinear map
must satisfy to be called a Lie bracket.
The commutator bracket thus turns the vector space of quantum operators
into a Lie algebra.
However, the commutator of two hermitian operators isn't hermitian.
To fix this and turn the hermitian operators by themselves into a Lie algebra,
just modify the definition of the bracket by multiplying
the above into some real multiple of the
imaginary unit i. For example:
[A,B] = i (AB - BA)
Derivative of an analytic function defined on operators :
The following relation holds for two operators whose commutator
is a scalar times Î (or, at least, if
their commutator commutes with the operator B ).
[ A, f (B) ] =
[A,B] f ' (B)
Proof:As usual,
f is an analytic function,
of derivative f '.
The relation being linear with respect to f,
it holds generally if it holds for
f (z) = z n...
The case n = 0 is trivial (zero on both sides) and an
induction on n completes the proof:
(2005-07-03) Operators Corresponding to Classical Quantities
Building on 6 operators for the
coordinates of position and momentum.
Bohr's correspondence
principle was a fuzzy set of recipes invoked by
Bohr
in his old quantum theory, before
Dirac's formulation.
It was based on the idea that a quantization of reality should yield back
classical laws in the limit of large quantum numbers.
In the new quantum theory, Dirac could achieve that
desirable goal in a more systematic way, by matching classical quantities
with quantum operators in the way described next.
A further improvement in the correspondence principle
resulted from Feynman's
sum-over-histories approach, itself
directly based on the deeper correspondence between classical probabilities
and quantum amplitudes (as presented above).
Only scalar physical quantities correspond to basic
observables (hermitian square matrices) within the relevant
Hilbert spaceL.
Physical vectors may also be considered, which
correspond to operators mapping a ket into a vector of kets
(i.e., an element of some Cartesian power
of L ).
Canonical Quantizations (Dirac, 1925) :
The key was a revelation which Paul Dirac
had during his Sunday walk on 20 September 1925.
Vaguely recalling the beautiful construct known as
Poisson brackets
in the Hamiltonian formulation of classical mechanics,
Dirac guessed those could well be the classical counterparts of quantum commutators.
The library was closed.
He had to wait until the next morning to refresh his memory and confirm his hunch:
To the Hamiltonian description of a classical system using generalized positions
qj and associated momenta pj correspond
quantum observables Qj and Pj such that
(using Kronecker delta notation):
[ Qj , Pk ] =
i
djk
The following table embodies
Dirac's correspondence principle
for those physical quantities which have such a classical analog...
The orbital angular momentum of a
pointlike particle does; its
spin doesn't.
According to the
above expressions,
the commutator of the two operators respectively associated with
the position x and the momentum
px along the same axis is the operator for
which the image of y is:
x ( h / 2pi )
¶y/¶x
-
( h / 2pi )
¶(xy)/¶x
=
( i h / 2p ) y
That commutator is thus
( i h / 2p ) Î
(where Î is the identity operator).
Similarly, we obtain the following expression for
the operators Âx
and Ây associated with components
Lx and Ly
of the orbital angular momentum:
[ Âx , Ây ]
= ( i h / 2p )
Âz
Proof :
Let's evaluate Âx (Ây
(y)) :
( h / 2pi ) 2
( y
¶
[ z ¶y/¶x
- x ¶y/¶z ] - z
¶
[ z ¶y/¶x
- x ¶y/¶z ] )
¶z
¶y
=
( h / 2pi ) 2
(
y ¶y/¶x
+
yz ¶2y/¶z¶x
-
yx ¶2y/¶z2
-
z2 ¶2y/¶y¶x
+
zx ¶2y/¶y¶z
)
All the second-order terms also appear in the like expression for
Ây (Âx
(y)) (which is obtained by swapping x and y).
So, they cancel in the difference:
[ Âx Ây -
Ây Âx ]
(y)
=
( h / 2pi ) 2
(
y ¶y/¶x
-
x ¶y/¶y
)
=
( i h / 2p )
Âz (y)
 =
Âx Ây Âz
For the 3-component column operator Â
associated with the ("orbital") angular momentum
L, this can be summarized:
 ´
 =
( i h / 2p ) Â
(2005-07-03) Noncommutativity and Uncertainty Relations
The link between commutators and expected
standard deviations.
When two observables A and B
are repeatedly measured from the same quantum state
| y >
the expected standard deviations are
Da
and Db.
( Da )2
=
< y |
A2
| y >
-
< y |
A
| y >2
( Db )2
=
< y |
B2
| y >
-
< y |
B
| y >2
The following inequality then holds
( Heisenberg's uncertainty relation ).
Da
Db
³
½ |
< y |
[A,B]
| y >
|
Proof:
Assuming, without loss of generality, that both
observables have zero averages (so the trailing terms
vanish in the above defining equations) this may be
identified as a type of Schwartz inequality, which may be proved
with the remark that the following quantity is nonnegative
for any real number x :
|| ( A + i x B )
| y > || 2
=
< y |
( A - i x B )
( A + i x B )
| y >
=
< y | (
x 2B 2
+
i x AB
-
i x BA
+
A2
) | y >
=
x 2 ( Db )2
+
x < y |
i[A,B]
| y >
+
( Da )2
The discriminant of this real
quadratic function of x can't be positive.
As we have established that
the observables for the position and momentum along the
same axis yield a commutator equal to
(ih/2p) Î, we have:
Dx Dpx
³
h/4p
Contrary to popular belief, the above doesn't simply state that two quantities
can't be pinpointed simultaneously (supposedly because "measuring one would
disturb the other").
Instead, it expounds that no experiments can be made on
identically prepared systems to determine separately both quantities
with arbitrary precision... At least whenever the following noncommutativity
condition holds:
< y | AB | y >
¹
< y | BA | y >
For a given quantum state, the uncertainty in the measurement of the momentum
along x always has some definite nonzero value. No experiment can be devised
which could achieve a better precision, even if the experimenter does not
care at all about estimating the position along x.
Likewise, for that same quantum state, there's a definite limit on the precision
with which the position along the x-axis can be determined,
even if we do not care at all about the momentum along x.
What Heisenberg's uncertainty relation specifies is that
no quantum states exists for which the product of
those two separate uncertainties is below h/4p.
This has absolutely nothing to do with one type of measurement
"disturbing" the other...
It's true that several measurements disturb each other,
but it's a completely different issue
(e.g., a precise momentum measurement
may leave the system in a new quantum state where the inherent
uncertainty in position may very well be much greater than originally).
The uncertainty principle goes much deeper than that.
In particular, it says that there's no way to create a perfectly focused beam
of identical particles with the same lateral velocity.
Even if you measure only either
the lateral position or the lateral momentum of any given particle
from the beam, your many measurements of both quantities will feature
standard deviations which cannot be better than what's imposed by the above
uncertainty relation. That's the way it is.
(2012-07-10) Transverse Certainties
Physical quantities whose commutator is a scalar
(i.e., the identity operator multiplied into some complex number)
are said to be conjugate of each other and the
dispersion in the measurement of one is inversely proportional to
the dispersion in the measurement of the other.
This is illustrated by the position and the momentum of a particle
along the same axis.
Conversely, when the observables commute, the eigenstate of one is
an eigenstate of the other and both quantities can be measured
simultaneously, without any dispersion, for all possible
values of either quantity.
Otherwise, some quantum states are eigenstates of one observable
but not the other, while others may be eigenstates of both.
For example, the magnitude of the impulsion (but not its direction)
can be measured with zero dispersion if the particle is found to
be at a location where the magnitude |y|
of the wave function is either zero or maximum:
y* ¶y / ¶x
=
y* ¶y / ¶y
=
y* ¶y / ¶z
= 0
That's because the commutator between the operators associated to the coordinate
position x and || p2 ||
vanish at such positions (the same being true for other coordinates):
[ x, ||p||2 ] | y >
=
x (-h2/4p2 )
Dy -
(-h2/4p2 )
D(xy)
=
(h2/2p2 )
¶y / ¶x
|< y | [ x, ||p||2 ] | y >
=
(h2/2p2 )
y* ¶y / ¶x
(2005-06-27) Nonrelativistic Postulate of Evolution with Time
Between measurements, a quantum state obeys Schrödinger's equation.
In nonrelativistic quantum theory, time (t) is not an observable in the
above sense, but a parameter along which things
evolve between measurements,
according to the following generalization of
Schrödinger's equation,
using the hamiltonian operatorH
(associated with the system's total energy) :
As an important example of the above general postulate,
we may retrieve the original equation of Schrödinger for a
nonrelativistic particle subjected to a scalar potential.
In that case, the total mechanical energy is given by:
(2015-10-03) What's time?
Time and energy are conjugate quantities.
The relation between time and energy in nonrelativistic quantum theory.
In nonrelativistic quantum mechanics, time
is just a parameter, not an observable with its own
uncertainty (equal to its standard deviation).
It makes sense to use some observable A as a clock
only if its average value
< y | A | y >
changes with time, in which case we may define
the time-uncertainty Dt
as the time in which that expected value changes by an amount equal to the clock's
standard deviation Da. That's to say:
We may also apply the previously established uncertainty relation
to the observables A and H
(knowing that, by definition, the standard deviation of the Hamiltonian H is
the uncertainty in energy DE). This gives:
Da
DE
³
½ |
< y |
[A,H]
| y > |
If we assume
< y | [A,H] | y >
to be nonzero, those three relations yield:
DE Dt
³
h/4p
So, even in the framework of nonrelativistic quantum mechanics we can obtain
rigorously an uncertainty relation which is the perfect counterpart of the
well-known uncertainty relation
between position and momentum along one spatial direction.
Time is to energy what spatial position is to linear momentum
(that's consistent with the tenets of Special
Relativity).
The above is established without invoking an observable whose commutator with
H would be a scalar multiple of Î
(advanced considerations, related to the
Stone-von Neumann theorem, would show that there's no such thing).
Mercifully, it's enough to have, for any given quantum state
| y > ,
some observable with a non-vanishing time-derivative.
We don't need to assume the dubious existence of a single clock which
would be valid in that sense for every possible quantum state...
(2007-07-16) Orbital Angular Momentum and Spin
Spin is a form of angular momentum without a classical equivalent.
The following argument was fully developed by
Elie Cartan (1869-1951) in 1913
from a purely geometrical standpoint (not involving Planck's
constant as such) as he investigated the
Lie algebra of the group of
three-dimensional rotations. Cartan thus demonstrated, ahead of
his time, how the idea of quantized spin is a consequence of
three-dimensional geometry.
The pioneers of quantum mechanics rediscovered those things in the 1920's.
In 1935, Cartan himself published a remarkable textbook on
his Theory of Spinors.
Let's investigate the properties of a vectorial
observable  which satisfies the fundamental property
previously established
in the case of the quantum operator associated with a classical
(orbital) angular momentum, namely:
 ´
 =
( i h / 2p ) Â
This pretty equation is merely a mnemonic for 3
commutation relations:
 =
Âx Ây Âz
[ Ây , Âz ] =
( i h / 2p ) Âx
[ Âz , Âx ] =
( i h / 2p ) Ây
[ Âx , Ây ] =
( i h / 2p ) Âz
The 3 components
Âx , Ây
and Âz are
scalar observables (i.e., square matrices with hermitian symmetry).
We introduce another such observable:
Therefore, those two things add up to zero, which means:
[ Â2 , Âz ] = 0
The above definition of Â2 ensures
that < y | Â2 |
y >
is nonnegative for any ket
|y>
(HINT: this is the sum of 3 real squares).
Therefore, this operator can only have nonnegative eigenvalues, which
(for the sake of future simplicity)
we may as well put in the following form, for some nonnegative number j.
j (j+1) (h/2p)2
The punch line will be that j is restricted
to integer or half-integer values.
For now however, we may just accept this expression
because it spans all nonnegative values
once and only once when j goes from zero to infinity.
So, j can be used to index every eigenvalue
of Â2.
Similarly, we may use another index m to identify the
eigenvalue m (h/2p)
of Âz . For now,
nothing is assumed about m (we'll show
later that 2m is an integer).
Since those two observables commute, there's an orthonormal
Hilbertian basis
consisting entirely of eigenvectors common to both of them.
We may specify it by introducing a third index n (needed
to distinguish between kets having identical eigenvalues
for both of our observables).
Those conventions are summarized by the following relations,
which clarify the notation used for base kets:
Â2
| n, j, m > =
j (j+1)
(h/2p)2
| n, j, m >
Âz
| n, j, m > =
m
(h/2p)
| n, j, m >
Cartan's proof of quantization, by finite descent (1913) :
To determine the restrictions that j and m must obey,
we introduce two non-hermitian operators,
conjugate of each other. They are collectively known as
ladder operators
and are respectively called lowering operator
(or annihilation operator)
and raising operator (or creation operator)
because it turns out that each transforms an eigenvector into
another eigenvector corresponding to a lesser or greater eigenvalue, respectively.
Â- =
Âx -
i Ây
and
Â+ =
Âx +
i Ây
Both commute with Â2
(because Âx and Ây do).
The following holds:
|| Â+
| n, j, m > || 2
=
< n, j, m | Â-Â+ | n, j, m >
Where
Â-Â+
=
Âx Âx
+
Ây Ây
+ i
[ Âx , Ây ]
=
Â2
-
Âz Âz
-
( h / 2p ) Âz
So,
|| Â+
| n, j, m > || 2
=
[ j(j+1) - m2
- m ]
( h / 2p )2
As the nonnegative square bracket is equal to
j (j+1) - m(m+1)
we see that m cannot exceed j.
We would find that (-m) cannot exceed j
by performing the same computation for
|| Â-
| n, j, m > ||. All told:
-j ≤ m ≤ j
Note that the above also proves that the ket
Â+ | n, j, m >
vanishes only when m = j. Likewise,
Â- | n, j, m >
is nonzero unless m = -j.
Except in the cases where they vanish,
such kets are eigenvectors of Âz
associated with the eigenvalue of index
m ± 1.
Let's prove that:
So, if | y > is an eigenvector of
Âz for
the eigenvalue m (h/2p), then:
ÂzÂ+
| y > =
(m+1) (h/2p)
Â+
| y >
Thus,
Â+
| y >
is either zero or an eigenvector of
Âz
associated with the value
(m+1) (h/2p).
The same is true of
Â-
| y >
with (m-1) (h/2p).
Since we know that m is between
-j and +j , we see that both
j-m and j+m must be integers
(or else iterating one of the two constructions above
would yield a nonzero eigenvector with a
value of m outside of the allowed range).
Thus, 2j and 2m must be integers (they are the
sum and the difference of the integers j+m and j-m).
If j is an integer, so is m.
If j is an half-integer, so is m
(by definition, an "half-integer" is half the value of an odd integer).
The above demonstration is quite remarkable:
It shows how a 3-component observable is quantized
whenever it obeys the same commutation relation
as an orbital angular momentum.
Although half-integer values of the numbers j and m
are allowed, those
do not correspond to an orbital momentum.
Indeed, let's show that orbital momenta
can only lead to whole values of j and m.
(2008-08-24) Pauli Matrices (1927)
& Spin of an Electron
Three traceless anticommuting Hermitian matrices with unit squares.
In 1927, Wolfgang Pauli (1900-1958)
introduced three matrices for use in the theory of electron spin.
Their eigenvalues are +1 and -1.
s1 = sx =
0 1
1 0
s2 = sy =
0 i
-i 0
s3 = sz =
1 0
0 -1
They have unit squares and anticommute:
sjsk =
- sksj
when j ¹ k.
They combine into a 3-vector of matrices verifying the crucial equation:
s ´ s =
2i s
Therefore, they provide an explicit representation of the
above type of "angular momentum" observables
in the simplest case
of only two values (eigenvalues). This is meant to describe
a lone fermion of spin ½, of which the electron
is the primary example.
The above discussion and notations apply directly to:
 = (h/4p)
s
(i.e., Âx = (h/4p)
sx , etc. )
In this simple case, we have
Â2 =
Âx2 +
Ây2 +
Âz2 =
3 (h/4p)2Î
The square of the spin of any electron;
is thus always equal to
3 (h/4p)2.
The observable corresponding to the projection of the electron spin
along the direction of the unit vector
u of Cartesian coordinates (x,y,z) is
Âu =
x Âx +
y Ây +
z Âz =
(h/4p)
z x + iy
x - iy -z
Since x2 + y2 + z2 = 1, the
eigenvalues of Âu are indeed always
± (h/4p).
Note that any Hermitian matrix with such opposite eigenvalues can be put in this
form. Thus, any quantum state is associated with an observable which will
confirm its orientation with certainty (probability 1).
In 1924, Pauli had identified a "two-valued quantum degree of freedom"
associated, in particular, with the valence electron of an alkali metal.
The introduction of this new quantum number allowed him to state his famous exclusion principle
(i.e., two electrons orbiting the same atom have different quantum numbers).
However, he strongly rejected the idea of the young
Ralph Kronig (1904-1995)
that this might be due to some intrinsic rotation of the electron.
Pauli discouraged Kronig from pursuing a "clever" idea which he pronounced to have
"nothing to do with reality".
Instead, the proposal was duly published by
Uhlenbeck and
Goudsmit,
who thus got the credit for the concept of electron spin.
Indeed, no classical rotation of something as small as an
electron could produce the required magnetic moment unless
the "surface of the electron" [sic] moved faster than light
(this objection was raised by H.A. Lorentz). However,
a pointlike object can be endowed with something similar to rotation.
One should simply refrain from dubious explanations relying on moving subparts...
(2023-03-08) Dirac's four 4×4 gamma matrices (1928).
Matrices quartered into either Pauli matrices
or trivial blocks (0, ±1).
Let's build four anticommuting matrices of dimension 4,
using 2×2 blocks equal either Pauli matrices
or the 2×2 identity I multipled into 0, +1 or -1.
There are essentially just two nondegenerate ways to do so, which we may respectively identify by the common names of the
metric signatures they induce
in the Clifford algebra of dimension 4 generated by them:
Euclidean : (+, +, +, +)
b0 =
I O
O -I
bi =
O sj
sj O
for j = 1,2,3
Minkowskian : (+, -, -, -)
g0 =
I O
O -I
gi =
O -sj
sj O
for j = 1,2,3
Although the former case has seen some usage,
The latter case is the star of the show in relativistic quantum mechanic.
The gamma notation is standard, the beta one is not, but one reduces to the other in a simple way:
b0 =
g0 and
bj =
g0 gj j = 1,2,3
The key propery in either case is that the matrices have unit squares
(with a change of sign when the metric signature calls for it) and that the four matrices anticommute pairwaise
for distinct indices. (HINT: so do the 3 Pauli matrices).
That makes all cross-products cancel pairwise when expanding a square, so we have nice relations:
( x0 b0 + x1 b1 +
x2 b2 + x3 b3 ) 2
=
x02 + x12 + x22 + x32
( ct g0 + x g1 +
y g2 + z g3 ) 2
=
c2t2 - x2 - y2
- z2
Both right-hand sides are understood to be the stated scalars
multiplied into the identity matrix, which may be omitted by convention.
The gamma (resp. beta) matrices are not closed under multiplication.
They generate an algebra of dimension 16.
Iterating Dirac's Trick
In the above construction, we went from n=3 mutually anticommutaive Pauli matrices of unit squares
in m=2 dimensions to n+1 = 4 gamma matrices which are likewise mutually anticoutative
with unit squares (up to a change of sign). (Actually, we get a fifth gamma matrix for free in the same
space of dimension 4 as the product of the first four.) This can be iterated to
spaces of square matrices of order 2 (Pauli), 4 (Dirac's gamma), 8, 16, 32, etc.
Original Form of Dirac's Equation (Paul Dirac, 1927)
(2008-08-26) Quantum Entanglement
The singlet and triplet
states of two entangled electrons.
According to the previous article, a
pure quantum state for the spin of a lone electron is represented
by a ket which is
a linear combination of the two eigenvectors of
sz
which we shall henceforth call "up" and "down":
| u > =
1 0
| d > =
0 1
This involves a priori two complex coefficients.
However, two kets that are complex multiples of each other represent the same quantum state,
so the specification of a state actually depends on just two
real numbers.
Another way to look at this is to remark
that such a quantum state is represented by a normalized
ket of unit length corresponding to either of two diametrically opposed
points on a unit sphere.
Such a thing is indeed specified by two real numbers: latitude and longitude
(although the global topology
is not that of a sphere because diametrically
opposite points are considered to be equivalent).
The juxtaposition of two such spins is represented by a linear combination
of four pairwise orthogonal unit kets in a 4-dimensional
Hilbert space :
| u,u >
| u,d >
| d,u >
| d,d >
In that space, a quantum state is described
by 6 independent real numbers
(4 complex coefficients modulo one complex scalar)
which is 2 more "degrees of freedom" than
what might be expected for the separate
description of two spins.
The extra possibilities are called entangled
states.
Consider the same observables as before for
the measurement of the first spin only.
Those operators do not change at all the components of the ket which
describe the second spin.
With a single spin, we saw that any given pure quantum state
was always a +1 eigenstate of a certain linear combination of
sx,
sy and
sz.
In particular, as all measurements of the corresponding quantity were
always equal to +1 so was their average.
Surprisingly, this no longer holds for the measurement of
a single spin in a two-spin system.
In particular, the following two states both yield a zero
average for the measurement of the first spin
along any direction :
Similarly, in either of those two quantum states,
the average measurement of the second spin along any direction
is also zero.
We may also consider a combined observable which gives the sum
of the two spins along some direction.
The result can only be +2, 0 or -2 and the average
is zero for both the singlet and triplet states.
However, much more is true for the singlet state,
since any measurement of the sum of the spins along any
direction always gives zero for the singlet state.
Not just a zero average but an actual zero measurement
every time !
Thus, if you measure the spin of one of the two electrons entangled
in a singlet state, you will know for sure
that a measurement of the spin of the other electron
along the same direction will give the opposite result. Always.
(2008-08-31) Bell's Inequalities
(John S. Bell, 1964)
Statistical relations which are violated in quantum mechanics.
Classically, the probabilities of events
can be broken down as sums of mutually exclusive events.
Such a decomposition implies the following inequality between
various joint probabilities of three events A, B and C:
P ( A & [not B] ) +
P ( B & [not C] ) ≥
P ( A & [not C] )
The picture shows that the event of the right-hand-side is
composed of the two mutually exclusive events shaded
in red, which also appear as components of the two events from
the left-hand-side. So, their probabilities add up
to something no greater than the left-hand-side sum.
This is known as Bell's Inequality.
In quantum mechanics, there are no such things as mutually exclusive
events (unless actual observations take place which
turn the quantum logic of virtual
possibilities into the more familiar statistics of
observed realities).
Thus, there's no reason why Bell's inequality should apply
to the calculus of virtual quantum possibilities.
Indeed, it doesn't in the
above case of a
singlet state.
(2015-01-25) Kochen-Specker theorem ("KS", 1967)
Definite values would violate the relations between physical quantities.
Using a topos perspective in
1998,
Chris J. Isham (1944-) and
Jeremy Butterfield (1954-)
have stated the KS theorem thusly:
It's impossible to assign values to all physical quantities whilst preserving the functional relations between them.
(2008-08-25) Higher-Order Spin
Equivalents of the Pauli matrices beyond spin ½.
A particle of spin j is
something which allows a measurement of its spin along any
direction to have 2j+1 values
(according to Cartan's argument).
Two measurement values are allowed for j=1/2,
3 values for j=1,
4 values for j=3/2,
5 values for j=2.
The relativistic case of massless particles is beyond the scope of this discussion:
The measured spin of a massless particle
can only be clockwise or counterclockwise, at full magnitude,
in the direction of motion (that would translate into only two possible
measurement results, for any nonzero value of j ).
The relevant
Hilbert space has dimension 2j+1 and the observables
for the three projections of angular momentum on three orthogonal
directions (in a right-handed configuration) can be expressed
as in the above special case (j=½)
using the counterparts of Pauli matrices
in a Hilbert space of 2j+1 dimensions, namely
three 2j+1 by 2j+1 matrices which combine into a "vector" verifying
the following compact commutation relation:
s ´ s =
2i s
Actual observables of angular momentum are simply
obtained by multiplying such matrices into the
half-quantum of spin
(h/4p).
Here's how we may construct such a thing: First we impose
wlg that
sz is diagonal
(that simply means we decide to use eigenvectors of
sz to form a basis
for our Hilbert space).
We do know the eigenvalues of
sz from
Cartan's argument, so
sz is entirely specified up
to the ordering of the (real) elements in the diagonal. We choose (arbitrarily)
to order our base kets so that those (distinct) eigenvalues appear in
decreasing order on the diagonal of
sz.
So, sz is simply the diagonal
matrix whose 2j+1 elements are
(2j, 2j-2, 2j-4, ... -2j).
We are looking for the hermitian matrix
sx
in terms of (j+1)(2j+1)3 scalar unknowns
(including 2j+1 real ones).
In the case j = 3/2 this would mean a total of
10 unknowns (6 complex and 4 real ones)
in a 4 by 4 matrix:
sx =
a b* c* d*
b e f* g*
c f h k*
d g k m
The reader is encouraged to use that explicit example, with
index-free notations, to embody
the following outline of a general derivation.
Now, sy is obtained
directly from the equation:
[ sz ,
sx ] =
2 i sy
This yields an expression of
sy
where each entry is proportional
to the corresponding (unknown) entry of
sx.
Next, we may use the relation:
[ sy ,
sz ] =
2 i sx
This tells us that all terms of
sx
(and, therefore, also those of
sy )
must vanish except at positions
adjacent to the main diagonal.
Now, we're faced with only 2j unknown
complex coefficients
(which are unconstrained, at this point)
and just one more commutation relation to satisfy, namely:
[ sx ,
sy ] =
2 i sz
It turns out that this final equation gives us the squares
of the absolute values
of the aforementioned remaining 2j unknowns.
Each of them is thus determined
up to an arbitrary phase factor
(for a total of 2j arbitrary multipliers of unit length).
In the following tabulation, we have chosen a "standard" convention
for those phase factors which makes all the coefficients of
sx real
and positive.
Spin j = 1/2 :
sx =
0 1
1 0
sy =
0 i
-i 0
sz =
1 0
0 -1
Spin j = 1 :
sx =
Ö2
0 1 0
1 0 1
0 1 0
sy =
Ö2
0 i 0
-i 0 i
0 -i 0
sz =
2 0 0
0 0 0
0 0 -2
Spin j = 3/2 :
sx =
0 Ö3 0 0
Ö3 0 2 0
0 2 0 Ö3
0 0 Ö3 0
sy =
0 iÖ3 0 0
-iÖ3 0 2i 0
0 -2i 0 iÖ3
0 0 -iÖ3 0
sz =
3 0 0 0
0 1 0 0
0 0 -1 0
0 0 0 -3
Spin j = 2 :
0 2 0 0 0
2 0 Ö6 0 0
0 Ö6 0 Ö6 0
0 0 Ö6 0 2
0 0 0 2 0
0 2i 0 0 0
-2i 0 iÖ6 0 0
0 -iÖ6 0 iÖ6 0
0 0 -iÖ6 0 2i
0 0 0 -2i 0
4 0 0 0 0
0 2 0 0 0
0 0 0 0 0
0 0 0 -2 0
0 0 0 0 -4
Relativistic arguments (beyond the scope of this discussion)
do not allow elementary particles beyond spin 2.
Composite objects with higher spins do not have a fixed value of
j. However, if their possible decay into things of lower spin is ignored,
they would behave like fictional high-spin objects, starting with:
The same pattern holds for any spin j :
The nth coefficient down the upper subdiagonal of
sx for spin j
is simply given by the expression:
(sx )n,n+1
=
Ö
n ( 2j + 1 - n )
exp ( i jn )
[ e.g., jn = 0 ]
If used, each phase factor applies to two matching elements in
sx and
sy which are above the
diagonal. The conjugate phase applies to the transposed elements (below the diagonal).
This would turn the ordinary (2x2) Pauli matrices into:
sx =
0 e-ij
eij 0
sy =
0 i e-ij
-i eij 0
sz =
1 0
0 -1
The eigenvectors of those three matrices are
respectively proportional to:
1 e-ij
and
-1 e-ij
1 i e-ij
and
-1 i e-ij
1 0
and
0 1
We may call twists the 2j such phase factors which are
part of sx
and sy.
For spin ½, the single twist can be eliminated by redefining
which axis (perpendicular to the z-axis) is associated with the twist-free version
of sx.
This works for a single spin but cannot be done simultaneously for several
spins... It's as if a spin possessed an internal phase
which indicates, so to speak, the actual angular position
in a "rotation" around a given axis.
The same trick can always be used to make the sum of the twists
vanish in a single higher spin, but what is the physical significance of the
2j-1 remaining degrees of freedom?
They seem to determine, in a nontrivial way, the relative positional
phases in the "rotations" around each direction of space.
In particular, what does j mean
in the following observables for spin 1 ?
sx =
Ö2
0 e-ij 0
eij 0 eij
0 e-ij 0
sy =
Ö2
0 i e-ij 0
-i eij 0 i eij
0 -i e-ij 0
sz =
2 0 0
0 0 0
0 0 -2
The columns in the following [unitary and hermitian] matrices are eigenvectors:
1 2
1 Ö2 e-ij 1
Ö2 eij 0 -Ö2 eij
1 -Ö2 e-ij 1
1 2
1 i Ö2 e-ij -1
-i Ö2 eij 0 -i Ö2 eij
-1 i Ö2 e-ij -1
1 0 0
0 1 0
0 0 1
(2005-06-30) Density operators = macrostates
(von Neumann, 1927)
Quantum representation of systems in
imperfectly known mixed states.
A microstate (or pure quantum state)
is represented by a normed ket
from the relevant Hilbert space, up to an irrelevant phase factor.
A more realistic macrostate is a statistical mixture
(called mixed state or Gemischt)
which can be represented by a unique [hermitian] density operatorr
with positive eigenvalues that add up to 1.
r =
å
pn | n > < n |
In particular, the unique density operator representing the pure quantum state
associated with the normed ket | y >
is given by the following expression, which is unaffected by phase factors
(since multiplying | y >
by a complex number of unit norm will multiply
< y | by the reciprocal).
r =
| y > < y |
A statistical mixture consisting of a proportion u of the macrostate
represented by r1
and a proportion 1-u of the macrostate
represented by r2
is represented by the following density operator:
r =
u r1 +
(1-u) r2
The trace of an operator
is the sum of the elements in its main diagonal
(this doesn't depend on the base).
All density operators have a trace equal to 1.
Conversely, all operators of trace 1 can be construed as density operators.
Tr ( Â ) =
ån < n | Â | n >
The measurement of any observableÂ
yields the eigenvalue a
with the following probability, involving the
projector onto the relevant eigenspace:
p ( a ) =
Tr ( r Pa )
Thus, systems are experimentally different if and only
if they have different density operators.
We may as well talk about r as
being a macrostate.
The average value resulting from a measurement of
 = åa a Pa is:
< Â > =
åa a
p(a)
=
åa
Tr ( r a Pa )
=
Tr ( r  )
Mere interaction with a measuring instrument turns the
macrostate r into åaPa r
Pa
Recording the measure a
makes it
Pa r
Pa /
Tr ( r Pa )
This is known as "Lüder's rule" or
Lüders' projection postulate.
It was first discussed in 1951 by Gerhart Lüders, in
"Über die Zustandsanderung durch den Messprozess"
(On the state-change
due to the measurement process) which appeared in
Annalen der Physik, 8 (6) 322-328.
An [analytic] function of an operator, like the logarithm of an operator,
is defined in a standard way:
In a base where the operator is diagonal, its image is the
diagonal operator whose eigenvalues are the images of its eigenvalues.
The Von Neumann entropy
S ( r ) is what
Shannon's
statistical entropy becomes
in this context. It is
defined in units of a positive constant k :
S ( r ) =
-k Tr ( r
Log ( r ) )
S is positive, except for a pure state
r = | y >
< y |
for which S = 0.
Algebraically, the following strict inequality holds, unless
r = r'.
S ( r ) <
-k Tr ( r
Log ( r' ) )
An isolated nonrelativistic system evolves according to
the Schrödinger-Liouville equation, involving its
hamiltonian H :
( ih / 2p )
dr/dt =
Hr
- rH
With thermal contacts, a quasistatic evolution has different rules (T and H vary).
Introducing the partition function (Z) :
Z = Tr exp ( - H / kT )
and
r = exp ( - H / kT ) / Z
The variation of the internal energy
U = Tr ( r H ) may be expressed as