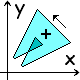AlisonWonder
(2002-06-23)
The Basics:
What is a derivative?
Let's give the traditional approach first.
This will be complemented by an abstract glimpse of the bigger picture,
which is more closely related to the way people actually use
derivatives, once they are familiar with them.
For a given real-valued function f of a real variable,
consider the slope (m)
of its graph at some point.
That is to say, some straight line
of equation y = mx+b (for some irrelevant constant b)
is tangent to the graph of f at that point.
In some definite sense, mx+b is the best linear approximation to f(x) when
x is close to the point under consideration...
The tangent line at point x may be defined as the limit of
a secant line intersecting a curve at point x and point x+h,
when h tends to 0.
When the curve is the graph of f, the slope of such a secant is equal to
[ f(x+h)-f(x) ] / h,
and the derivative (m) at point x is therefore the limit of that quantity, as h tends to 0.
The above limit may or may not exist, so the derivative of f at point x may or
may not be defined. We'll skip that discussion.
The popular trivia question concerning the choice of the letter "m"
to denote the slope of a straight line (in most US textbooks) is discussed
elsewhere.
Way beyond this introductory scope, we would remark that
the quantity we called h is of a vectorial nature
(think of a function of several variables),
so the derivative at point x is in fact a tensor
whose components are called partial derivatives.
Also beyond the scope of this article are functions of a complex variable,
in which case the above quantity h is simply a complex number,
and the above division by h remains thus purely numerical (albeit complex).
However, a complex number h (a point on the plane) may approach zero in a variety of ways
that are unknown in the realm of real numbers (points on the line).
This happens to severely restrict the class of functions
for which the above limit exists.
Actually, the only functions of a complex variable which have a derivative
are the so-called analytic functions
[essentially: the convergent sums of power series].
The above is the usual way the concept of derivative is
often introduced.
This traditional presentation may be quite a hurdle to overcome,
when given to someone who may not yet be thoroughly familar with
functions and/or limits.
Having defined the derivative of f at point x,
we define the derivative functiong = f' = D( f )
of the function f,
as the function g whose value g(x) at point x is the
derivative of f at point x.
We could then prove, one by one, the algebraic rules listed
in the first lines of the following table.
These simple rules allow most derivatives to
be easily computed from the derivatives of just a few elementary functions,
like those tabulated below
(the above theoretical definition is thus rarely used in practice):
u and v are functions of x,
whereas a, b and n are constants.
One abstract approach to the derivative concept
would be to bypass (at first) the relevance to slopes,
and study the properties of some derivative operator D,
in a linear space of abstract functions
endowed with an internal product (´),
where D is only known to satisfy the following two axioms
(which we may call linearity and Leibniz' law,
as in the above table):
D(au + bv)
=
a D(u) + b D(v)
D( u ´ v )
=
D(u) ´ v + u ´ D(v)
For example, the product rule imposes that D(1) is zero [in the argument of D,
we do not distinguish between
a function and its value at point x, so that "1" denotes the function whose value
is the number 1 at any point x].
The linearity then imposes that D(a) is zero, for any constant a.
Repeated applications of the product rule give the derivative of x raised to the
power of any integer, so we obtain (by linearity) the correct derivative
for any polynomial.
(The two rules may also be used to prove the chain rule for polynomials.)
A function that has a derivative at point x (defined as a limit)
also has arbitrarily close polynomial approximations about x.
We could use this fact to show that both definitions of the D operator coincide,
whenever both are valid
(if we only assume D to be continuous, in a sense which we won't make more precise here).
The above abstarction is directly accessible at the elementary level.
Beyond that, a very fruitful viewpoint is totally different,
In the Theory of Distributions,
as a pointwise product like the
above (´) is not even defined, whereas everything revolves
around the so-called convolution product
(*), which has the following strange property concerning
the operator D:
D( u * v )
= D(u) * v
= u * D(v)
To differentiate a convolution product (u*v),
differentiate either factor!
(2021-07-17) Logarithmic Derivative f '/ f The logarithmic derivative of a product is the sum of those of its factors.
When the logarithm of a function is well-defined, the logarithmic derivative
is the derivative of the logarithm.
However, the logarihmic derivative of a nonzero differentiable function
is always well-defined, even when the logarithm isn't
(as is the case for negative functions or for complex-valued functions,
where the logarithm could only be defined as a multivalued
function).
(2002-06-26)
What's the "Fundamental Theorem of Calculus" ?
Once known as Barrow's rule, it states that,
if f is the derivative of F, then:
F(b) - F(a) =
é ë
F(x)
ùb ûa
=
ób õa
f (x) dx
In this, if f and F are real-valued functions of a real variable,
the right-hand side represents the area between the curve
y = f (x) and the x-axis (y = 0),
counting positively what's above the axis and negatively
[negative area!] what's below it.
Any function F whose derivative is equal to f
is called a primitive of f
(all such primitives simply differ by an arbitrary additive constant,
often called constant of integration).
A primitive function is often called an indefinite integral
(as opposed to a definite integral which is a mere number,
not a function, possibly obtained as the difference of the values of the
primitive at two different points).
The usual indefinite notation is:
F(x) =
ò f (x) dx
At a more abstract level, we may also call Fundamental Theorem of Calculus
the generalization of the above expressed in the language of differential forms,
which is also known as Stokes' Theorem, namely:
(2010-11-21)
Example involving complex exponentials
What is the indefinite integral of cos(2x) e 3x ?
That function is the real part of a
complex function of a real variable:
(cos 2x + i sin 2x) e 3x =
e i (2x)e 3x
= e (3+2i) x
Since the derivative of exp(a x) / a is
exp(a x) we obtain, conversely:
ò
e(3+2i) x dx =
e(3+2i) x / (3+2i) =
e3x (cos 2x + i sin 2x) (3-2i) / 13
The relation we were after is obtained as the
real part of the above:
ò
cos(2x) e 3x dx =
(3 cos 2x + 2 sin 2x) e 3x / 13
(2005-02-06) Integration by parts
One way to reduce the computation of one integral to another.
This method was first published in 1715 by
Brook Taylor (1685-1731).
The product rule states that the derivative
(uv)' of a product of two
functions is u'v+uv'.
When the integral of some function f is sought,
integration by parts is a minor art form which attempts to use this
backwards, by writing f as a product u'v of two functions, one of which
(u') has a known integral (u). In which case:
ò f dx
= ò u'v dx
= uv
- ò uv' dx
This reduces the computation of the integral of f to that of
uv'. The tricky part, of course, is to guess what choice of
u would make the latter simpler...
The choice u' = 1 (i.e.,
u = x and v = f ) is occasionally useful. Example:
ò ln(x) dx
=
x ln(x) - ò (x/x) dx
=
x ln(x) - x
Another classical example pertains to Laplace transforms
( p > 0 )
and/or Heaviside's operational calculus, where all integrals are
understood to be definite integrals
from 0 to +¥
(with a subexponential function
f ):
ò f'(t) exp(-pt) dt
=
- f (0) +
p ò f (t) exp(-pt) dt
Last but not least, integration by part may produce similar
integral remainders.
Iterating such a process may generate famous summations, like
Taylor's expansion,
Darboux's formula, Euler-Maclaurin formula...
(2021-07-08) Wallis' Integrals (Wallis, 1655)
Integration by parts establishes a recurrence relation.
The Wallis integral of order n is the definite integral:
In =
ó p/2 õ0
sinn t dt =
ó p/2 õ0
cosn t dt
As the integrand is a pointwise decreasing function of the integer n,
these integrals form a decreasing sequence.
Trivially, I0 = p/2 and I1 = 1.
Let's integrate by parts the Wallis integral of order n+2 when n ≥ 0 :
ó p/2 õ0
sinn+2 t dt =
é ë
- sinn+1 t cos t
ù p/2 û 0
+ (n+1)
ó p/2 õ0
sinn t cos2 t dt
On the right-hand-side, the square bracket vanishes and we may replace cos2 t by
1 - sin2 t to obtain
In+2 = (n+1) ( In - In+2 ).
Therefore:
(n+2) In+2 = (n+1) In
So, we have a recurrence for even orders and another one for odd orders.
I2n
=
2n-1
2n-3
3
1
p
2n
2n-2
4
2
2
=
(2n)! p
22n+1 n!2
I2n+1
=
2n
2n-2
4
2
1
2n+1
2n-1
5
3
=
22n n!2
(2n+1)!
Therefore, I2n I2n+1 = p / (4n+2).
As the sequence is decreasing, the
sandwich theorem implies that consecutive terms are
asymptotically equivalent. This makes I2n2
equivalent to p/4n. In other words:
In ~ ( p/2n )1/2
Combined with the above expression for I2n (or I2n+1) that equivalence
is what allowed James Stirling (1692-1770) to
derive his famous formula
for the asymptotic equivalent of n! (1730).
The Wallis Product :
One popular way to present the fact that the ratio I2n+1 / I2n tends
to one as n tends to infinity is to state that the following product is convergent :
rkanchan (2000-10-17)
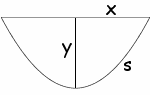
What is the perimeter of a parabolic curve,
given the base length and height of [the] parabola?
Choose the coordinate axes so that your parabola has equation y = x2/2p
for some constant parameter p.
The length element ds along the parabola is such that
(ds)2 = (dx)2 + (dy)2, or
ds/dx = Ö(1+(dy/dx)2)
= Ö(1 + x2/p2).
The length s of the arc of parabola from the apex (0,0) to the point
(x, y = x2/2p) is simply the following integral of this
(in which we may eliminate x or p,
using 2py = x2 ).
s
=
(x/2)
Ö
1 + x2/p2
+ (p/2) ln(
Ö
1 + x2/p2
+ x/p )
=
y
Ö
1 + p/2y
+ (p/2) ln(
Ö
1 + 2y/p
+
Ö
2y/p
)
=
(x/2)
Ö
1 + (2y/x)2
+ (x2/4y) ln(
Ö
1 + (2y/x)2
+ 2y/x )
For a symmetrical arc extending on both sides of the parabola's axis, the
length is 2s (twice the above).
If needed, the whole "perimeter" is 2s+2x.
97-Bravo (2006-06-22)
What's the top height of a (parabolic) bridge?
If a curved bridge is a foot longer than its mile-long horizontal span...
Let's express all distances in feet (a mile is 5280 ft).
Using the notations of the previous article, 2x = 5280,
2s = 5281, u = x/p = 2y/x = y/1320
s / x = 5281 / 5280
= ½
Ö
1 + u2
+ (1/2u) ln(
Ö
1 + u2
+ u )
For small values of u, the right-hand side is roughly 1+u2/6.
Solving for u the equation thus simplified, we obtain
Ö(6/5280)
= 0.033709993123...
The height y is thus roughly equal to that quantity multiplied by
1320 ft ,
which is nearly 44.4972 ft.
This approximation is valid for any type of smooth enough curve.
It can be refined for the parabolic case using successive approximations to solve
for u the above equation. This yields u = 0.0337128658566...
which exceeds the above by about 85.2 ppm (ppm = parts per million) for
a final result of about 44.5010 ft. Our first approximation would've
satisfied any engineer before the computer era.
The solution is best expressed as 44½ ft.
Ronaldo
(2008-03-27; e-mail) Length of a sagging horizontal cable:
How long is a cable which spans 28 m horizontally and sags 300 mm?
Answer : Surprisingly, just about 28.00857 m...
Under its own weight, a uniform cable without any rigidity
(a "chain") would actually assume the shape of a
catenary.
In a coordinate system with a vertical y-axis and centered on its apex,
the catenary has the following cartesian equation:
Measured from the apex at x = y = 0,
the arclength s along the cable is:
s = a sh (x/a)
Those formulas are not easy
to work with, unless the parameter a is given.
For example, in the case at hand (a 28 m span with a 0.3 m sag)
we have:
x = 14
y = 0.3
So, we must solve for a (numerically) the transcendantal
equation:
0.3 / a =
2 sh2 (7/a)
This yields a = 326.716654425...
Therefore :
2s = 2a sh (14 / a)
= 28.00856959...
Thus, an 8.57 mm slack produces a 30 cm sag
for a 28 m span.
The parameter a is
the radius of curvature
at the curve's apex. If it's large enough,
we may find a good approximation to the relevant transcendental
equation by equating the sh function to its (small)
argument:
y/a =
2 sh2 (x/2a)
yields
a » x2 / 2y
whereby s = a sh (x/a)
»
x ( 1 + x2 / 6a2 )
»
x ( 1 + 2y2 / 3x2 )
This gives 2s
»
2x ( 1 + 8/3 (y/2x)2 )
= 28.0085714... in the above case.
This is indeed a good approximation to the aforementioned exact result.
Parabolic Approximation :
If we plug the values x = 14 and y = 0.3
in the above formula for the exact length of a
parabolic arc, we obtain:
2s = 28.0085690686...
Circular Approximation :
A thin circular arc of width 2x and of height y
has a length
2s =
x2+y2
arcsin (
2 xy
) = 28.00857064...
y
x2+y2
In fact, all smooth approximations to a flat enough
catenary will have a comparable precision, because this is what results from equating
a curve to its osculating circle at the lowest point.
The approximative expression we derived above in the case of the catenary
is indeed quite general:
2s »
2 x [ 1 +
8/3 (y/2x) 2 ]
abandonedmule (2001-04-10)
Arch of a Cycloid
Find the ratio, over one revolution, of the distance moved by a wheel rolling
on a flat surface to the distance traced out by a point on its rim.
As a wheel of unit radius rolls on the x-axis,
the trajectory of a point on its circumference is a cycloid,
whose parametric equation is :
x = t - sin(t)
y = 1 - cos(t)
This curve was first studied by Marin Mersenne
(1588-1648) around 1615.
The parameter t is the abscissa of the wheel's center.
In the first revolution of the wheel (one arch of the cycloid),
t goes from 0 to 2p.
The length of one full arch of a cycloid ("cycloidal arch")
was first worked out in the 17th century by
Evangelista Torricelli (1608-1647),
just before the advent of the calculus. Let's do it now with modern tools:
Calling s the curvilinear abscissa (the length along the curve), we have:
The length of the whole arch is the integral of this when t goes
from 0 to 2p
and it is therefore equal to 8,
[since the indefinite integral is -4 cos(t/2)].
On the other hand, the length of the trajectory of the wheel's center
(a straight line) is clearly 2p
(the circumference of the wheel).
In other words, the trajectory of a point on the circumference
is 4/p times as long as the trajectory of the center,
for any whole number of revolutions (that's about 27.324% longer, if you prefer).
The ratio you asked for is the reciprocal of that,
namely p/4 (which is about 0.7853981633974...),
the ratio of the circumference of the wheel to the length of the cycloidal arch.
However, the result is best memorized as:
"The length of a cycloidal arch is 4 times the diameter of the wheel."
Pradip Mukhopadhyay
(from Schenectady, NY. 2003-04-07; e-mail)
What is the [indefinite] integral of (tan x)1/3 dx ?
An obvious change of variable is to introduce y = tan x
[ dy = (1+y2 ) dx ],
so the integrand becomes
y1/3 dy / (1+y2 ).
This suggests a better change of variable, namely:
z = y2/3 = (tan x)2/3[ dz = (2/3)y-1/3 dy ],
which yields z dz = (2/3)y1/3 dy,
and makes the integrand equal to the following rational function of z,
which may be integrated using standard methods
(featuring a decomposition into 3 easy-to-integrate terms):
As (1-z+z2 )
is equal to the positive quantity
¼ [(2z - 1)2 + 3] , we obtain:
ò(tan x)1/3 dx
=
¼ ln(1-z+z2 )
+
¼Ö3 arctg((2z-1)/Ö3)
- ½ ln(1+z)
where z stands for | tan x | 2/3
(D. B. of Grand Junction, CO. 2000-10-12)
A particle moves along the parabola
y = Ö(-x)
so its x coordinate decreases
at the rate of 8 m/s. When x = -4, how fast is the change in
the angle of inclination of the line joining the particle to the origin?
We assume all distances are in meters.
When the particle is at a negative abscissa x,
the (negative) slope of the line in question is
y/x = Ö(-x)/x and the corresponding
(negative) angle is thus:
a = arctg(Ö(-x)/x)
[In this, "arctg" is the "Arctangent" function, which is also spelled "atan"
in US textbooks.]
Therefore, a varies with x at a (negative) rate:
da/dx = -1/(2´Ö(-x)(1-x)) (rad/m)
If x varies with time as stated, we have dx/dt = -8 m/s, so
the angle a varies with time at a (positive) rate:
da/dt = 4/(Ö(-x)(1-x)) (rad/s)
When x is -4 m, the rate dA/dt is therefore 4/(Ö4
´5) rad/s = 0.4 rad/s.
The angle a,
which is always negative, is thus increasing at a rate of 0.4 rad/s when
the particle is 4 meters to the left of the origin (rad/s = radian per second).
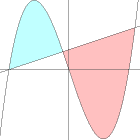
massxv2 (2002-05-18)
What's the area bounded by the following curves?
The curves intersect when f(x) = g(x),
which translates into x3 - 10x - 3 = 0.
This cubic equation factors nicely into
(x + 3) (x2 - 3x - 1) = 0 ,
so we're faced with only a quadratic equation...
To find if there's a "trivial" integer which is a root of a polynomial with integer
coefficients [whose leading coefficient is ±1],
observe that such a root would have to divide the constant term.
In the above case, we only had 4 possibilities to try, namely -3, -1, +1, +3.
The abscissas A < B < C of the three intersections are therefore:
A = -3 ,
B = ½ (3 - Ö13)
and
C = ½ (3 + Ö13)
Answering an Ambiguous Question :
The best thing to do for a "figure 8", like the one at hand,
is to compute the (positive) areas of each of the two lobes.
The understanding is that you may add or subtract these,
according to your chosen orientation of the boundary:
The area of the lobe from A to B (where f(x) is above g(x))
is the integral of f(x)-g(x) = x3 - 10x - 3
[whose primitive is x4/4 - 5x2 - 3x] from A to B,
namely (39Ö13 - 11)/8, or about 16.202...
The area of the lobe from B to C (where f(x) is below g(x)) is the integral of
g(x)-f(x) from B to C,
namely (39Ö13)/4, or about 35.154...
The area we're after is thus either
the sum (±51.356...) or
the difference (±18.952...) of these two,
depending on an ambiguous boundary orientation...
If you don't switch curves at point B,
the algebraic area may also be obtained
as the integral of g(x)-f(x) from A to C
(up to a change of sign).
(2002-05-18, 2005-08-03) Signed Planar Areas Consistently Defined
A net planar area is best defined as the
apparent area of a 3D loop.
The area surrounded by a closed planar curve may
be defined in general terms, even when the curve does cross itself
many times...
The usual algebraic definition of areas depends on the orientation
(clockwise or counterclockwise)
given to the closed boundary of a simple planar surface.
The area is positive if the boundary runs counterclockwise around the surface,
and negative otherwise
(by convention,
the positive direction of planar angles is always counterclockwise).
In the case of a simple closed curve [without any multiple points]
this is often overlooked, since we normally consider only
whichever orientation of the curve makes the area of its interior positive...
The clear fact that there is such an "interior" bounded by any given closed planar curve
is known as "Jordan's Theorem".
It's a classical example of an "obvious" fact with a rather
intricate proof.
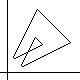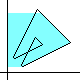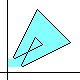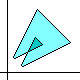
However, when the boundary has multiple points (like the center of a "figure 8"),
there may be more than two oriented boundaries for it,
since we may have a choice at a double point:
Either the boundary crosses itself or it does not (in the latter case,
we make a sharp turn,
unless there's an unusual configuration about the intersection).
Not all sets of such choices lead to a complete tracing of the whole loop.
At left is the easy-to-prove "coloring rule" for a true self-crossing
of the boundary, concerning the number of times the ordinary area
is to be counted in the "algebraic area" dicussed here.
It's nice to consider a given oriented closed boundary
as a projection of a three-dimensional loop whose apparent area
is defined as a path integral.
brentw (Brent Watts
of Hickory, NC. 2001-04-13/email)
[How do you generalize the method] of variation of parameters when solving
differential equations (DE) of 3rd and higher order?
For example: x''' - 3x'' + 4x = exp(2t)
In memory of Lucien Refleu 1920-2005 who
taught me this and much more, many years ago.
As shown below,
a high-order linear DE can be reduced
to a system of first-order linear differential equations in several variables.
Such a system is of the form:
X' = dX/dt = AX + B
X is a column vector of n unknown functions of t.
The square matrix A may depend explicitely on t.
B is a vector
of n explicit functions of t, called forcing terms.
The associated homogeneous system
is obtained by letting B = 0.
For a nonconstant A, it may be quite difficult to find n independent solutions
of this homogeneous system (an art form in itself)
but, once you have them, a solution of the forced system
may be obtained by generalizing to n variables the method
(called "variation of parameters") commonly used for a
single variable. Let's do this using only n-dimensional notations:
The fundamental object is the square matrix W formed with the n columns corresponding
to the n independent solutions of the homogeneous system.
Clearly, W itself verifies the homogeneous equation:
W' = AW
It's an interesting exercise in the manipulation of
determinants to prove that det(W)' = tr(A) det(W)
(HINT: Differentiating just the i-th line of W gives a matrix
whose determinant is the product of det(W) by the i-th component
in the diagonal of the matrix A).
Since det(W), the so-called "Wronskian", is thus
solution of a first-order linear DE, it's proportional to the exponential of
some function and is therefore either nonzero everywhere or zero everywhere.
(Also, the Wronskians for different sets of homogeneous solutions must be proportional.)
Homogeneous solutions that are linearly independent at some point are therefore
independent everywhere and W(t) has an inverse for any t.
We may thus look for the solution X to the nonhomogeneous
system in the form X = WY :
So, Y is simply obtained by integrating W-1 B
and the general solution of the forced system may be expressed as follows,
with a constant vector K (whose n components are
the n "constants of integration").
This looks very much like the corresponding formula for a single variable :
X(t) = W(t) [ K +
ò t
W-1(u) B(u) du ]
Linear Differential Equation of Order n :
A linear differential equation of order n has the following form
(where ak and b are explicit functions of t):
x(n) +
an-1 x(n-1) + ... +
a3 x(3) + a2 x" + a1 x' + a0 x
= b
This reduces to the above system
X' = AX + B with the following notations :
A =
X =
B =
0
1
0
0
...
0
0
x
0
0
0
1
0
...
0
0
x'
0
0
0
0
1
...
0
0
x"
0
0
0
0
0
...
0
0
x(3)
0
...
...
...
...
...
...
...
...
...
0
0
0
0
...
0
1
x(n-2)
0
-a0
-a1
-a2
-a3
...
-an-2
-an-1
x(n-1)
b
The first n-1 components in the equation X' = AX+B
merely define each component of X as the derivative of the previous one,
whereas the last component expresses
the original high-order differential equation.
Now, the general discussion above applies
fully with a W matrix whose first line consists of n independent solutions of the
homogeneous equation (each subsequent line is simply the derivative of its predecessor).
We need not work out every component of W-1
since we're only interested in the first component of X...
The above boxed formula tells us that we only need the first component
of W(t)W-1(u)B(u) which may be written G(t,u)b(u),
by calling G(t,u) the first component of
W(t)W-1(u)Z, where Z is a vector whose component are all zero,
except the last one which is one.
G(t,u) is called
the Green function associated to the given homogeneous equation.
It has a simple expression (given below) in terms of a ratio of determinants computed
for independent solutions of the homogeneous equation.
(Such an expression makes it easy to prove that
the Green function is indeed associated to the equation itself and not to a particular
set of independent solutions, as it is clearly invariant if you replace any solution by
some linear combination in which it appears with a nonzero coefficient.)
For a third-order equation with homogeneous solutions A(t), B(t) and C(t), the expression of
the Green function (which generalizes to any order) is:
G(t,u) =
A(u)
B(u)
C(u)
A'(u)
B'(u)
C'(u)
A(t)
B(t)
C(t)
A(u)
B(u)
C(u)
A'(u)
B'(u)
C'(u)
A"(u)
B"(u)
C"(u)
It's also a good idea to define G(t,u) to be zero when u>t,
since such values of G(t,u) are not used in the integral
ò t G(t,u) b(u) du.
This convention allows us to drop the upper limit of the integral,
so we may write a special solution of the inhomogeneous equation
as the definite integral
(from -¥ to +¥,
whenever it converges):
ò G(t,u) b(u) du.
If this integral does not converge (the issue may only arise when u goes to
-¥), we may still use this formal expression by considering
that the forcing term b(u) is zero at any time t earlier than whatever happens to be the
earliest time we wish to consider.
(This is one unsatisfying way to reestablish some kind of
fixed arbitrary lower bound for the integral of interest when the only natural one,
namely -¥, is not acceptable.)
In the case of the equation x''' - 3x" + 4x = exp(2t), three independent solutions are
A(t) = exp(-t),
B(t) = exp(2t), and
C(t) = t exp(2t). This makes the denominator in the above (the "Wronskian")
equal to 9 exp(3u) whereas the numerator is
(3t-3u-1)exp(u+2t)+exp(4u-t).
With those values, the integral of G(t,u)exp(2u)(u)du when u goes from 0 to t
turns out to be equal to
f(t) = [ (9t2-6t+2)exp(2t) - 2 exp(-t) ]/54, which is therefore a
special solution of your equation. The general solution may be expressed as:
x(t) = (a + bt + t2/6) exp(2t) + c exp(-t)
[ a, b and c are constant ]
Clearly, this result could have been obtained without this heavy artillery:
Once you've solved the homogeneous equation and
realized that the forcing term is a solution of it,
it is very natural to look for an inhomogeneous solution of the form
z exp(2t) and find that z"=1/3 works.
That's far less tedious than computing and using the associated Green's function.
However, efficiency in this special
case is not what the question was all about...
(2001-04-13) Convolutions and the Theory of Distributions
An introduction to the epoch-making approach of Laurent Schwartz.
The above may be dealt with using the elegant idea of
convolution products among distributions.
The notorious Theory of Distributions occurred to the late
Laurent
Schwartz (1915-2002) "one night in 1944".
For this, he received the first
Fields Medal
ever awarded to a Frenchman, in 1950.
Schwartz taught at Polytechnique from 1958 to 1980.
(He taught mefunctional analysis in the Fall of 1977.)
A linear differential equation with constant coefficients
(an important special case) may be expressed as a convolution
a * x = b.
The convolution operator * is bilinear,
associative and commutative.
Its identity element is the
Delta distribution d
(dubbed Dirac's "function").
Loosely speaking, the Delta distribution d
would correspond to a "function" whose integral is 1,
but whose value at every point except zero is zero.
The integral of an ordinary function which is zero almost everywhere
would necessarily be zero.
Therefore, the d distribution cannot possibly
be an ordinary function: Convolutions must be put in the proper context of the
Theory of Distributions.
A strong case can be made that the convolution product is the notion that gives rise
to the very concept of distribution.
Distributions had been used loosely by physicists for a long time, when
Schwartz finally found a very simple mathematical definition for them:
Considering a (very restricted) space D of so-called test functions,
a distribution is simply a linear function which associates a scalar
to every test function.
Although other possibilities have been studied (which give rise to less
general distributions) D is normally the so-called Schwartz space
of infinitely derivable functions of compact support
These are perfectly smooth functions vanishing outside of a bounded domain,
like the function of x which is
exp(-1 / (1-x 2 ))
in [-1,+1] and 0 elsewhere.
What could be denoted f(g) is written
f*g instead.
This hint of an ultimate symmetry between the rôles of f and g
is fulfilled by the following relation, which holds whenever the integral exists
for ordinary functions f and g.
[f*g](t) =
ò f(t-u)g(u) du
This relation may be used to establish commutativity
(switch the variable to v = t-u, going from
+¥ to -¥
when u goes from
-¥ to +¥).
The associativity of the convolution product is obtained
by figuring out a double integral.
Convolutions have many stunning properties.
In particular, the Fourier transform of the convolution product of two functions is
the ordinary product of their Fourier transforms.
Another key property is that the derivative of a convolution product may be obtained
by differentiating either one of its factors:
(f*g)'
=
f'*g
=
f*g'
This means the derivatives of a function f can be expressed as convolutions, using
the derivatives of the d distribution
(strange but useful beasts):
f = d * f
f' = d'
* f
f'' = d''
* f
etc.
If the n-th order linear differential equation
discussed above has constant coefficients,
we may write it as f*x = b
by introducing the distribution
f = d(n) +
an-1 d(n-1) + ... +
a3 d(3) +
a2 d" +
a1 d' +
a0 d
Clearly, if we we have a function such that
f*g=d,
we will obtain a special solution of the inhomogeneous equation as
g*b.
If you translate the convolution product into an integral, what you obtain is thus
the general expression involving a
Green functionG(t,u)=g(t-u),
where g(v) is zero for negative values of v.
The case where coefficients are constant is therefore much simpler than
the general case:
Where you had a two-variable integrator, you now have a single-variable one.
Not only that, but the homogeneous solutions are well-known
(if z is an eigenvalue
of multiplicity n+1 for the matrix involved, the product of exp(zt) by any polynomial of
degree n, or less, is a solution).
In the important special case where all the eigenvalues are
distinct, the determinants involved in the expression of
G(t,u)=g(t-u) are essentially
Vandermonde determinants,
or Vandermonde cofactors
(a Vandermonde determinant is a determinant where each column consists of the successive
powers of a particular number).
The expression is thus fairly easy to work out and may be put into the following simple form,
involving the characteristic polynomial P for the equation
(it's also the characteristic
polynomial of the matrix we called A in the above).
For any eigenvalue z, the derivative P'(z)
is the product of the all the differences between
that eigenvalue and each of the others (which is what Vandermonde expressions entail):
With this, x = g*b is indeed
a special solution of our original equation f*x = b
brentw (Brent Watts of Hickory, NC.
2001-05-05)
Laplace Transforms
How do you use Laplace transforms to solve this differential system?
Initial conditions, for t=0 : w=0, w'=1, y=0, y'=0, z= -1, z'=1.
The (unilateral) Laplace transform F = L( f ) of a function f is given by:
F(p) =
ó ¥ õ0
f (t) exp(-pt) dt
That's defined, for p > 0, whenever the integral makes sense.
For example, the Laplace transform of a constant k is the function F such that
F(p) = k/p.
Integrating by partsf' (t) exp(-pt) dt gives a simple relation
between the respective Laplace transforms
L( f') and L( f ) of
f' and f :
L( f' ) =
- f (0) + p L( f )
This may be iterated, starting with:
L( f'' )
=
- f ' (0) + p L( f ' )
=
- f ' (0) - p f(0) + p2 L( f )
Thats the basis for the Operational Calculus, perfected in 1893 by
Oliver Heaviside (1850-1925),
to translate many practical systems of differential
equations into algebraic ones.
(Originally, Heaviside was interested in the transient solutions to the simple differential
equations arising in electrical circuits).
Let's use capital letters to denote Laplace transforms of
lowercase functions (W=L(w), Y=L(y), Z=L(z)).
The differential system at hand translates into:
(p2 W - 1 - 0p)+ Y + Z = -1/p
W + (p2 Y - 0 - 0p) - Z = 0
-(pW - 0) -(pY - 0) + (p2 Z - 1 + p) = 0
In other words:
p2 W + Y + Z = 1 -1/p
W + p2 Y - Z = 0
-pW -pY + p2 Z = 1-p
Solve for W,Y and Z and express the results as simple sums
(that's usually the tedious part,
but this example is designed to be simpler than usual):
W = 1/(p2 +1)
Y = p/(p2 +1) - 1/p
Z = 1/(p2 +1) - p/(p2 +1)2
The last step is to go from these Laplace transforms back to the original
(lowercase) functions of t, with a reverse lookup using a table of
Laplace transforms, similar to the (short) one provided below.
w = sin(t)
y = cos(t) - 1
z = sin(t) - cos(t)
With other initial conditions, solutions may involve various linear combinations
of no fewer than 5 different types of functions
(namely: sin(t), cos(t), exp(-t), t and the constant 1),
which would make a better showcase for Operational Calculus than this
particularly simple example...
Below is a small table of Laplace transforms, which is
sufficient to solve the above for any set of initial conditions,
by reverse lookup :
brentw (Brent Watts of Hickory, NC.
2001-03-19)
Counterexamples
1) What's an example of a function f for which the integral
from -¥ to +¥
is well-defined for |f(x)| dx but not for f(x) dx.
2) What's an example of a function f for which the opposite is true?
1) Consider any nonmeasurable
set E within the interval [0,1]
(Zermelo's Axiom of Choice
guarantees one such set exists)
and define f(x) to be:
+1 if x is in E
-1 if x is in [0,1] but not in E
0 if x is outside [0,1]
The function f is not Lebesgue-integrable,
but its absolute value clearly is (|f(x)| is equal to 1 on [0,1] and
0 elsewhere).
That was for Lebesgue integration. For Riemann integration, you may construct a simpler
example by letting the above E be the set of rationals between 0 and 1.
2) On the other hand, the function sin(x)/x is a simple example of a function
which is Riemann-integrable over
]-¥,+¥[
(Riemann integration can be defined over an infinite interval,
although it's not usually done in basic textbooks),
whereas the absolute value |sin(x)/x| is not.
Neither function is Lebesgue-integrable over
]-¥,+¥[,
although both are over any finite interval.
araimi (2001-04-10)
Functional Calculus
Show that: f (D)[eax y] = eaxf (D+a)[y] ,
where D is the operator d/dx.
If f (x) is the converging sum
of all terms
an xn
(for some scalar sequence
an ),
f is called an analytic function
[about zero] and it can be defined
for some nonnumerical things that can be added,
scaled or "exponentiated"...
The possibility of exponentiation to the power of a nonnegative
integer reasonably requires the definition of some kind of
multiplication
with a neutral element
(in order to define the zeroth power)
but that multiplication need not be commutative or even associative.
Power-associativity
suffices (which is implied, in particular, by the alternativity
obeyed by octonions).
Here we merely focus on the multiplication of square matrices of finite
sizes which corresponds to the composition of linear functions in
a vector space of finitely many dimensions.
If M is a finite square matrix representing some linear operator
(which we shall denote by the same symbol M for convenience)
f (M) is defined as a power series of M.
If there's a vector basis in which the operator M is diagonal,
f (M) is diagonal
in that same basis, with f (z) appearing on the diagonal of f (M)
wherever z appears in the diagonal of M.
Now, the differential operator D is a linear operator like any other,
whether it operates on a space of finitely many dimensions
(for example, polynomials of degree 57 or less) or infinitely many dimensions
(polynomials, formal series...).
f (D) may thus be defined the same way.
It's a formal definition which may or may not have a numerical counterpart,
as the formal series involved may or may not converge.
The same thing applies to any other differential operator,
and this is how f (D) and f (D+a)
are to be interpreted.
To prove that a linear relation holds when f appears homogeneously
(as is the case here),
it is enough to prove it for any n
when f (x)=xn:
The relation is trivial for n=0
(the zeroth power
of any operator is the identity operator) as the relation translates
into exp(ax)y = exp(ax)y.
The case n=1 is:
D[exp(ax)y] = a exp(ax)y + exp(ax)D[y] = exp(ax)(D+a)[y].
The case n=2 is obtained by differentiating the case n=1 exactly like the case n+1 is
obtained by differentiating case n, namely:
Dn+1[exp(ax)y] = D[exp(ax)(D+a)n(y)]
= a exp(ax)(D+a)n[y] + exp(ax) D[(D+a)n(y)]
= exp(ax) (D+a)[(D+a)n(y)] = exp(ax) (D+a)n+1[y].
This completes a proof by induction for any f (x) = xn,
which establishes the relation for any analytic function f,
through summation of such elementary results
(when such a summation makes sense).
Let's consider the class C of all functions whose
(improper) integral from
-¥ to
+¥
is well-defined (or "convergent") at least as
a Cauchy principal value.
The following is trivially true for the case u(x) = x-a.
" f Î C ,
ò f (x) dx
=
ò f (u(x)) dx
What was discovered by Cauchy in 1823
(and rediscovered later by Schlömilch) is that this
is also true in one nontrivial family of cases:
u(x) = x - k/x (for any constant k ≥ 0)
In 1983,
Glasser pointed out that the above was more generally true for any finite sum of the following type:
u(x) = x - a
- k1/(x-t1)
- k2/(x-t2)
- ...
- kn/(x-tn)
We may interpret the sum as a Riemann sum whose limit defines an integral
and find the following substitution also acceptable for any nonnegative distribution
k (provided only that the convolution integral converges):
(2020-03-05)
Feynman's Trick
("differentiate under the integral sign").
Make the integral parametric and find its derivative along that parameter.
Richard Feynman (1918-1988) was instrumental in the popularization
of this technique, which he had learned as a teenager from the 1926 textbook
Advanced Calculus by
Frederick S. Woods (1864-1950).
The general rule for differentiation under the integral is ultimately just
a joint application the fundamental theorem of calculus
and the chain rule, using
partial derivatives.
Sometimes dubbed Leibniz integral rule,
this gives the expression of the derivative along a parameter p of an integral whose integrand and
bounds of integrations may depend on p :
d
ò
b (p)
f (p,t) dt = f (p,b)
db
- f (p,a)
da
+
ò
b (p)
¶
f (p,t) dt
dp
a (p)
dp
dp
a (p)
¶p
One important special case is when the lower bound (a) is constant and the upper bound of integration
is simply b(p) = p :
d
ò
p
f (p,t) dt = f (p,p)
+
ò
p
¶
f (p,t) dt
dp
a
a
¶p
The simplest special case is when both bounds (a and b) are constant:
Straight Leibniz Integral Rule
d
ò
b
f (p,t) dt =
ò
b
¶
f (p,t) dt
dp
a
a
¶p
Richard Feynman popularized the
use of this formula to work out definite integrals which
are otherwise difficult. The trick is to introduce
an ad hoc parametric family of functions
f (p,t) which includes the function f (t)
whose definite integral we seek. E.g., f (t) = f (0,t).
g (p) =
ò
b
f (p,t) dt
g (0) =
ò
b
f (t) dt
a
a
The derivative of g is then obtained by
differentiating under the integral sign, according to the above
Leibniz integral rule.
We're thus left with a differential equation for g
whose full solution would yield the value of g (0) we're after.
(If we need several successive differentations under the integral sign,
we obtain a higher-order differential equation.)
Let's build on this result with
f (t) = sin2(t)/t2 and f (p,t) = sin2(pt)/t2
This yields
¶pf (p,t) = sin(2pt)/t.
So, the Leibniz rule gives an integral equated
to the above result by linear substitution (u = 2pt). Namely:
g' (p) =
ò
+¥
sin(u)/u du
= p
-¥
Therefore, g (p) = p p (since g (0) = 0)
and g (1) = p , which is to say:
(2021-06-19)
The Malmsten family of integrals include Vardi's integral.
These tough integrals, featuring Log Log x, were first evaluated in 1842.
These are due to Carl Johan Malmsten, but were rediscovered several times.
The record was set straight recently
(2012)
by Iaroslav V. Blagouchine
(b. 1979, PhD in 2001 and 2010). However, the simplest member of the family
remains associated with the name of Ilan Vardi
(1957-, PhD 1982) who rediscovered it in 1988.
 rkanchan (
rkanchan (
 massxv2 (
massxv2 (