brentw (Brent Watts, NC.
2000-12-07)
Defining Real Numbers...
What's the definition of a Cauchy sequence?
In a metric space,
a Cauchy sequence is a sequence U whose
far terms are within
a vanishing distance of each other... This is to say that,
given any small positive quantity e,
there's an integer N(e) such that,
for any p and q both larger than N(e),
the distance from U(p) to U(q)
is always less than e.
In this, the distance from x to y is usually |x-y| using the ordinary norm,
but more exotic possibilities exist, including
the p-adic metric.
The concept was first introduced by
Augustin Cauchy (1789-1857)
as a nice way to
characterize convergent sequences of real numbers without
referring explicitely to the limits they converge to.
( Cours d'analyse de l'Ecole Polytechnique, 1821.)
A convergent sequence is always a Cauchy sequence.
The converse is only true in a complete space (like the real numbers);
it's not true for the rationals.
In fact a complete metric space can be defined as
a metric space in which every Cauchy sequence converges.
Following Georg Cantor (1845-1918)
one usually defines real numbers, as equivalence classes of
rational Cauchy sequences. Two sequences
U and V are considered equivalent if the limit of U(n)-V(n) is zero.
For example, the constant sequence U(n) = 1 is a Cauchy sequence
equivalent to the Cauchy sequence
V(n) = 1-(0.1)n ,
whose first terms are:
So, both sequences define the same
real number (the number 1).
Any real number which has a finite decimal expansion also has an infinite
one, ending with infinitely many nines.
Other numbers have just a single
decimal expansion.
This confuses many beginners,
as they wrestle with the definition of real numbers.
There's another (equally valid) way to define real numbers, which predates the above.
It's based on Dedekind cuts
which turn out to be more difficult to manipulate than Cauchy sequences...
In the realm of real numbers, proving that a sequence converges and proving it's a
Cauchy sequence are just two aspects of the same thing.
Therefore, we'll choose an example
of a sequence in the the field of rationals (a notoriously incomplete space,
as was first glimpsed by a disciple of
Pythagoras, probably
Hippasus of Metapontum, about 2500 years ago).
Consider the rational sequence u, recursively defined via:
First you may want to prove that u(2n) is an increasing sequence and that u(2n+1)
is a decreasing one, whereas u(2m+1) is greater than any u(2n) for any pair n,m.
With the additional remark that u(2n+1)-u(2n) tends toward zero as n tends to
infinity, you've got all the ingredients to prove that, for p and q greater than n,
|u(p)-u(q)| is less than
|u(n)-u(n+1)|
and thus tends to zero when n tends to infinity.
In other words, the sequence u is a rational Cauchy sequence.
On the irrationality of the constant of Pythagoras
The above should come as no surprise to anyone who knows about the irrational limit
of u (namely Ö2),
a "special" number which was not at all taken for granted 2500 years ago:
The irrationality of what is still sometimes referred to as the
constant of Pythagoras
is said to have prompted
the sacrifice to the gods of 100 oxen (a so-called hecatomb)...
(2016-05-24) Determining the convergence of a series.
Exploring the boundary between convergent and divergent series.
Convergence tests for series
amount to a minor art form. They're an unavoidable part of an undergraduate education in mathematics.
As discussed elsewhere on this site,
there's much more to a series of terms an
than the sequence Am of its partial sums.
However, that's what classical analysis focuses on
(a viewpoint formalized by Cauchy in 1821):
Am =
m
an
å
n=0
The series is said to be convergent, of sum A,
iff the sequence
of its partial sums is a convergent sequence of limit A.
In which case, we write:
A =
¥
an
å
n=0
In the particular case of a real series whose terms are alternatively
positive and negative, this happens if and only if the terms of the series
tend to zero. Otherwise, this necessary condition is not sufficient,
as demonstrated by the case of the harmonic series.
A series is said to be absolutely convergent
when the series formed by the absolute values of its terms converges.
The same terminology can also be used for series whose terms are
complex,
hypercomplex or, more generally,
belong to a normed vector space
(the norm of a vector being corresponds to the absolute value of a number).
Convergence Tests for Positive Series :
The ratio test.
The root test.
Comparison with an integral.
In asymptotic analysis, critical cases
often involve cascades of logarithms:
L0 (x) = x
and
Lk+1 (x) = Log | Lk (x) |
an ~ a/ (
L0m0 (n)
L1m1 (n) ...
Lkmk (n) )
If all exponents are equal to 1, then the series diverges.
Otherwise, the series converges iff
the first exponent which differs from 1 is greater than 1.
Proof : The only critical case is when all exponents are equal to
1, with the possible exception of the last one. This can be settled
by comparing the series with an integral, because of the following
indefinite integrals.
ó õ
x
dt
=
Lk+1 (x)
L0(t) L1(t) ... Lk(t)
ó õ
x
dt
=
Lk (x) 1-m
if m ¹ 1
L0(t) L1(t) ... Lk(t)m
1-m
Other cases are settled by termwise comparisons with series of this type.
The idea for this convergence test originates with
Joseph Bertrand
(1822-1900) who introduced it for the case k = 2 in 1842
(cf. Série de Bertrand).
(2021-07-13) A piece of mathematical folklore:
If the series of term an > 0 converges,
so does the series Öan / n.
Because the two positive series an
and 1/n2 are convergent, all their partial sums are bounded
by their respective sums A and B. We may then use the
Cauchy-Schwartz
inequality to obtain, for any m :
(
m å n=0
Öan / n
)
2
≤
m å n=0
an
m å n=0
(1/n) 2
≤ A B = A
p2 6
So, all partial sums of the targeted series are bounded by
A½ p/Ö6.
Generalization :
The same argument proves the convergence of the series
Öan/nk
if k > ½.
johnrp (John P. of Middletown, NJ. 2000-10-14)
Can you rearrange the following infinite series so that its sum equals 43?
1 -1/2 +1/3 -1/4 +1/5 -1/6 +1/7 -1/8 +1/9 -1/10 ...
Yes. In fact such a thing can be done for any "target sum" S (here S=43) with any series
which is convergent but not absolutely convergent (that is, the series of absolute values
does not converge). That's known as the
Riemann series theorem
or also Riemann's rearrangement theorem.
This applies here, because the series involved converges to
a well-known constant while the series of absolute values
is the harmonic series, which has been
known to diverge since the 14th century (at least).
Let's discuss the construction in general terms:
Take just as many positive terms of the series as necessary to exceed S
(that's always possible, as explained below), then take as many negative terms to have the
partial sum fall below S, then use positive terms again to go above S, switch to negative
terms to go below S again, etc.
Note that, as advertised above, it is always possible to add enough terms of the series to
make up for any (positive or negative) difference between the current sum and the target S.
That's because the series of the absolute values is divergent (so both the series
of negative terms and the series of positive terms must be divergent, or else the whole
series would not be convergent).
In this process (at least after the first step) the difference between S and any partial sum
never exceeds the magnitude of the term added at the latest "switch" from negative to
positive (or vice-versa).
Since the magnitudes of such terms tend to zero, partial sums tend toward S.
S is therefore the sum of the rebuilt series.
In 1910, Waclaw Sierpinski (1882-1969)
further showed that any target sum could be achieved by rearranging terms of only one sign
(e.g., just the negative terms) in any convergent series which isn't absolutely convergent.
When a convergent series remains convergent (with unchanged sum) regardless of
the order of its terms, it's said to be unconditionally convergent.
This is the case when the series is absolutely convergent
(i.e., when the series formed by the norms of its terms converges).
In a vector-space of finite dimension, there are no others.
However, in a space of infinite dimension, the latter
term is stronger: some unconditionally convergent series may exist which are
not absolutely convergent.
(HINT: Consider the series whose n-th term is
(1/n) un if the Euclidean norm is used with
an infinite set of unit vectors u which are pairwise orthogonal).
Oresme's proof of the divergence of the harmonic series :
To apply the above to the question at hand, we have to show that the
following so-called harmonic series diverges:
Around 1350,
Nicole Oresme (1323-1382)
published one elementary way to do so, based on the remark that
the series is bounded from below by the series obtained by replacing 1/n with 1/q,
where q is the lowest power of 2 greater than or equal to n:
By grouping equal terms in that series, we see that the partial sum
up to the term of rank q=2p is simply equal to 1+p/2.
The partial sum of the harmonic series up to that rank is therefore no less than 1+p/2.
This means that such partial sums will eventually exceed any preset bound,
no matter how high. The series (slowly) diverges ;
its limit is infinity.
(2012-10-25) Decreasing divergent series whose minimum converges!
Such a counterintuitive monstrosity can be constructed very simply
from any convergent series with decreasing positive
terms un (e.g., un = 1/n).
We'll build two divergent series of terms an
and bn such that:
un =
min ( an , bn )
Let's choose a sequence of indices p(0) = 0 < p(1) < p(2) < p(3) < ...
such that p(i+1) - p(i) > 1/ui
If p(2i) ≤ n < p(2i+1) , then an = up(2i)
and bn = un
If p(2i+1) ≤ n < p(2i+2) , then an = un
and bn = up(2i+1)
The sum of all terms an when n goes from p(2i)
to p(2i+1)-1 is greater than 1, by construction, so the
an series diverges!
So does the bn series, for similar reasons.
Strictly speaking, the two series described are merely nonincreasing
but minor details could be adjusted to make them decreasing ones.
(Brent Watts of Hickory, NC.
2001-04-13)
How do you show that the sequence
f n : x ® xn
converges for each x in the closed interval [0,1]
but that the convergence isn't uniform?
The simple convergence of a sequence of functions is just pointwise convergence.
In this case, the limit of xn is clearly 0 when x is in [0,1[ and 1 when x=1.
The sequence f n thus converges and its limit is
the function f defined over [0,1] which is zero everywhere except at point 1,
where f (1) = 1.
Now, simple convergence does not tell you much about the limit.
The limit of continuous functions may not be continuous (this is what happens here).
Worse, the integral of the limit may not be equal to the limit of the integrals:
Consider, for example, the sequence of functions gn on [0,1]
for which gn(x) is n2x when x is in [0,1/n],
n(2-nx) when x is in [1/n,2/n] and zero elsewhere.
The pointwise limit of gn(x) is always zero (x=0 included,
since gn(0)=0 for any n).
Yet, the integral of gn is always equal to 1, for any n>1.
This is why the notion of uniform convergence was introduced: We say that a sequence
of functions fn defined on some domain of definition D converges
uniformly to its limit f when it's always possible for any positive quantity
e to exhibit a number N(e) such
that whenever n is more than N(e), the quantity
|fn(x)-f(x)| is less than e,
for any x in D. (Note that a "domain of definition" is not necessarily a "domain"
in the sense of an open region, ita est.
Whenever it's critical, make sure to specify
which meaning of "domain" you have in mind.)
Uniform convergence does imply that the integral of the
(uniform) limit is the limit of the integrals. It also implies that the (uniform) limit
of continuous functions is continuous.
Since you have a discontinuous limit here, the convergence can't possibly be uniform...
The above settles the question, but it can also be
shown directly that it's not possible for a given
(small enough) quantity e>0
to find an N such that f n(x)
would be within e of its limit for any x whenever n>N.
Indeed, for 0<e<1,
any x in [e1/n,1[
is such that fn(x) exceeds e.
The convergence is uniform within any interval
strictly smaller than [0,1[. It's not uniform over [0,1[ itself,
although the limit is continuous.
brentw (Brent Watts of Hickory, NC.
2001-04-14)
[...] Explain the concept of Darboux integrals.
Before Lebesgue took a radically different
(and better) approach, several definitions of integration were
proposed which involved dividing the interval of integration [a,b]
into a finite number of arbitrarily small segments : a = x0 < x1 < ... < xn = b
where xk+1 - xk ≤ e
Each author then defined a certain finite sum (see below)
depending on a given function f which was said to be
integrable (in the sense of Cauchy, Riemann, etc.)
if that sum has a limit as e tends to zero,
regardless of the chosen subdivisions
(the limit being the integral of f
on [a,b]). Viz:
Cauchy:
å (xk+1-xk)
f (xk) [This definition is now obsolete.]
Riemann:
å (xk+1-xk) f (sk)
where sk may be anywhere between xk and xk+1
Darboux (lower):
å (xk+1-xk)
Lk where Lk is the
greatest lower bound of f (x) for x in [xk+1-xk]
Darboux (upper):
å (xk+1-xk)
Uk where Uk is the
least upper bound of f (x) for x in [xk+1-xk]
The last two sums correspond to the lower and upper Darboux integrals.
The nice thing is that a function f is Riemann-integrable
if and only if its lower Darboux integral equals its upper Darboux integral.
The Riemann Integral was introduced by Bernhard Riemann
(1826-1866) in his Habilitationsschrift (1854)
(2014-08-09) Theory of Integration (Lebesgue, 1902)
Measure Theory. Lebesgue measure. Lebesgue Integrals.
The foundations of the modern theory of integration were laid down in the
1902 doctoral dissertation of
Henri Lebesgue (1875-1941)
under Emile Borel (1871-1956).
Lebesgue realized that slicing the "area"
delimited by a function into horizontal slices rather than vertical ones
would lead to a notion of integral that is far more satisfying than all
previous attempts.
The caveat is that the Lebesgue Integral
requires a careful definition of the
measure l of such horizontal slices,
which may be quite intricate...
ób õa
f (x) dx
= sign (b-a)
ó +¥ õ-¥
l ({x : (x-a)(x-b) < 0 & f (x) = y}) y dy
Both sides are equal if they are well-defined as Riemann integrals (possibly
improper ones, understood as limits).
However, the right-hand-side can make sense even when the left-hand-side doesn't.
In that case, the left-hand-side becomes a notation for the new concept of
Lebesgue integral.
The above remains valid, with the usual sign convention, when a > b.
That important practical point fully justifies the added complication of the above definition,
but Lebesgue integrals are best viewed as integrals over a non-oriented
measurabledomain of integration I which need not be an
interval (such as I = [a,b] ).
That entails a simpler general relation:
ó õI
f (x) dx
=
ó +¥ õ-¥
l ({ x Î I : f (x) = y }) y dy
Unlike Riemann integration, Lebesgue integration doesn't depend on the topology or ordering of the real
numbers and is thus easily generalized to other realms...
This is fundamentally different from the equally-important generalization of oriented
integration over smooth manifolds, intimately related to differential forms.
The classic example of a function which is Lebesgue-integrable but not Riemann-integrable is
the Dirichlet function,
f = 1Q (the
indicator of the rationals) whereby
f (x) is 1 when x is rational and 0 otherwise.
Being countable the set of the rationals
()
has zero Lebesgue measure.
Therefore, 1Q has a zero Lebesgue integral.
(HINT :
The integrand in the above right-hand-side is always zero.) It's not Riemann-integrable because
its two Darboux integrals are different (one is zero,
the other is b-a).
brentw (Brent Watts of Hickory, NC.
2000-11-25)
How do I evaluate the Fourier series of the function
f (x) = x(2p-x)
in the interval 0 < x < 2p ?
If a function
f (x) = ½
[ f (x-) + f (x+)]
has period 2p, then its
Fourier expansion is defined via:
f (x)
ao
¥
å
n=1
[ an cos(nx) + bn sin(nx) ]
2
The coefficients an
and bn are twice the
average values of cos(nx) f (x) and
sin(nx) f (x).
They're given by Euler's formulas :
an
1
ò
2p
0
f (x) cos(nx) dx
p
bn
1
ò
2p
0
f (x) sin(nx) dx
p
For an even function, like the one at hand, the b-coefficients are all
zero and we are only concerned with the first formula, giving the a-coefficients.
(Conversely, the a-coefficients would all be zero for an odd function.)
In the case at hand, we integrate by parts
twice over the interval
[0,2p] when n is nonzero (for
n = 0 we just integrate a quadratic function).
Thus, an is -4/n2
if n ¹ 0,
whereas ao is
4p2/3.
All told, we obtain:
x (2p-x)
2p2
4
¥
å
n=1
cos(nx)
[ For x between 0 and 2p ]
3
n2
The Basel Problem :
For x = 0, the above may serve as
a proof of the famous result at right, obtained by
Euler in 1735: The sum
of the reciprocals of all nonzero perfect squares is equal to
p2/6
p2
¥
å
n=1
1
6
n2
The problem of finding the exact value of that sum was posed by
Pietro
Mengoli in 1644. It was once known as the
Basel Problem,
after the hometown of Jacob
Bernoulli, who was first in a long list of notorious mathematicians (including
Leibniz)
who failed to discover the above solution.
Euler first worked it out numerically to 20 decimal
places (earlier in 1735) using the
Euler-Maclaurin
formula. He identified the value as
p2/6 before he could justify that.
brentw (Brent Watts of Hickory, NC.
2001-03-05)
How does one prove the relation at right?
Consider the odd function f (x) of period 2p
which equals
2x/p when x is in the
interval
[-p/2,p/2].
Euler's formulas give its Fourier expansion:
f (x)
8
¥ å n=0
(-1)n
sin(2n+1)x
p2
(2n+1)2
Integrate that to obtain the expansion of a primitive g(x) of f (x), namely:
g(x)
C
8
¥ å n=0
(-1)n
cos(2n+1)x
p2
(2n+1)3
The constant C is the average of g(x) over one full period.
It depends on which value we choose for g(0).
With g(0)=0, we have
g(x)=x2/p
for x between 0 and p/2.
Because of the symmetry about x=p/2,
the average C is:
C = g(p/2) = p/4.
Plug this value of C in the above relation at point x=0 (where g(x)=0 and cos((2n+1)x)=1),
to obtain the value
p3/32
for the sum we were after.
Dirichlet's Beta Function (and Euler Numbers) :
Consider the following expression, which generalizes the above.
Here, we're primarily concerned with integral (positive) values of z,
but this function
b (called Dirichlet's Beta Function)
may be defined by analytic continuation
over the entire complex plane. It has no singularities.
b(z)
¥ å n=0
(-1)n
(2n+1)z
The above shows that b(3) =
p3/32.
Differentiating f (x), instead of integrating it, would have given
b(1) = p/4,
a result which is commonly obtained by computing the value of the
arctangent function at x=1, using its
Taylor expansion about 0.
It's worth noting that the above method may be carried further with
repeated integrations. Every other time, such an integration gives an
exact expression for the alternating sum of some new power of the
reciprocals of odd integers. In other words, we obtain the value of
b(k) for any odd k,
and it happens to be a rational
multiple of p k :
b(1) = p/4
The general expression is
b(2n+1)
(p/2) 2n+1
| E2n |
2(2n)!
b(3) = p3/32
b(5) = 5p5/1536
b(7) = 61p7/184320
b(9) = 277p9/8257536
b(11) = 50521p11/14863564800
In this, | E2n | is a nonnegative integer.
The Euler number
En is defined as the coefficient of zn/n!
in the Taylor expansion of 1/ch(z)
[where ch is the hyperbolic cosine function;
ch(z) = (ez +e-z )/2].
Starting at the index n = 0, the sequence of
(signed) Euler numbers is:
We may also consider the secant function 1/cos(z)
which has the same expansion as
1/ch(z) except that all the coefficients are positive, so that:
¼ px
/ cos(½ px)
=
å n
b(2n+1) x 2n+1
There does not seem to be any similar expression for even powers. In fact,
b(2) is currently defined as an independent
fundamental mathematical constant, the so-called
Catalan Constant:
G = 0.915965594177219015...
This is the exact opposite of the situation for nonalternating sums, where
even powers correspond to an exact expression in terms of a rational multiple of the
matching power of p, whereas odd powers do not
[that's an open conjecture].
brentw (Brent Watts of Hickory, NC.
2000-11-21)
How do you prove the following relation?
The relation
åm ån u(m) v(n)
=
[ åmu(m) ]
[ ånv(n) ]
holds whenever the series involved are absolutely convergent
(which is clearly the case here).
Therefore, we only have to establish the following simpler equality:
(p/a)
coth(pa)
¥
å
m = -¥
1
m2 + a2
The sum on the right-hand side looks like a series of Fourier coefficients.
For what periodic function?
Well, it's not difficult to see that the correct denominator is obtained
for the continuous even function of period 2p
which equals cosh(ax)
if x is in the interval [-p,p].
When x is in that interval, the Fourier expansion has two equivalent
forms (using a-m = am ):
cosh(ax)
ao
¥
å
m = 1
am cos(mx) =
½
¥
å
m = -¥
am cos(mx)
2
Euler's formulas give
am =
[2a(-1)m/p]
sinh(pa) / (m2 + a2 ).
At the point x = p,
we have cos(mx)= (-1)m
and the above relation thus translates into the desired equality [just divide both sides by
(a/p) sinh(pa)].
brentw (Brent Watts of Hickory, NC.
2001-04-14)
How do you use the Fourier series for the function
f(x) = ex for x in ]0,2p[
to find the sum [S] of the series 1/(k2 + 1) ?
[ k=1 to ¥ ]
Use Euler's formulas to compute the Fourier coefficients of f(x).
Note that if you consider f as a function of period
2p equal to exp(x) in
]0,2p[,
it has a jump discontinuity at any point x=2np
(where n is any integer).
This means (and it's important for the rest)
that the Fourier series converge to the half-sum of the left limit and the right limit
at such points of discontinuity,
in particular the value at point 0 is
[exp(2p)+1]/2.
Now, the computation of the Fourier coefficients is easy if you remark that
exp(x)cos(kx) and exp(x)sin(kx)
are the real and imaginary parts of exp((1+ki)x)
(it's clear we'll only need the real part, but I'll pretend I didn't notice).
The indefinite integral of that is simply
exp((1+ki)x)/(1+ki), which we may also express as
exp((1+ki)x) (1-ki)/(1+k2).
The definite integral from 0 to 2p is thus
(exp(2p)-1)(1-ki)/(1+k2).
The Fourier coefficients are obtained by multiplying this by
1/p and using the real and imaginary part separately.
All told:
f(x) =
[exp(2p)-1]/p
(½ + SUM[ k=1 to ¥,
(cos(kx) - k sin(kx))/(1+k2) ] )
All you have to do is apply this to x=0
(this is why we did not really need the coefficients of sin(kx)).
With the above remark to the effect that the LHS really is
[f(x-)+f(x+)]/2 at any jump discontinuity like x=0, we obtain:
[exp(2p)+1] / 2 =
[exp(2p)-1] / p ( ½ + S )
where S is the sum we were after. Therefore:
S = p/2 - ½ + p /
[ exp(2p)-1 ] = 1.076674047...
That's also a special case (a = 1) of the relation obtained
above in the form:
p coth(p) = 1 + 2 S
brentw (Brent Watts of Hickory, NC.
2000-11-28)
Overshoot
[...] Please explain the Gibbs phenomenon of Fourier series.
At a point x where a function f has a jump discontinuity, any partial sum of
its Fourier series adds up to a function that has an "overshoot"
(i.e., a dampened oscillation) whose initial amplitude is about 9%
of the value of the jump J=|f(x+)-f(x-)|.
This amplitude is not reduced by adding more terms of the Fourier series.
It's not difficult to prove that, with n terms, the maximum value of the overshoot
occurs at/near a distance of p/2n on either side of x.
(You may do the computation with any convenient function having a jump J;
I suggest f(x)=sign(x)J/2 between
-p and p.
Adding a continuous function to that would put you back to the "general"
case without changing the nature or amplitude of the Gibbs oscillations.)
When n tends to infinity, the maximum reached by the first overshoot
oscillation is about 8.948987% of the jump J.
This value is precisely (2G/p-1)/2,
where G is known as the Wilbraham-Gibbs Constant:
G
=
ó p õ0
sin(q)/q dq
=
1.8519370519824661703610533701579913633458...
This is sometimes called "the 9% overshoot",
as it is about 9% of the total jump J.
[It's 18% (17.89797...%) when half the jump (J/2) is used as a unit.]
This tells you exactly what kind of convergence is expected from a Fourier series
about a discontinuity of f.
For a small h, you can always increase the number of Fourier terms so that Gibbs
oscillations are mostly confined to the very beginning of the interval [x,x+h].
This resembles the convergence to zero of the sequence of functions
f (n,x)
defined as being equal to 4nx(1-nx) for x between 0 and 1/n, and zero elsewhere.
f (n,x) always reaches a maximum value of 1 for x=1/2n.
That sequence does converge to zero, but it's not uniform convergence!
Same thing with partial Fourier sums in a neighborhood of a jump discontinuity...
brentw (Brent Watts of Hickory, NC.
2000-12-08)
What is the Cauchy principal value (PV) of an integral?
If f has no singularities, the principal value (PV) is just the ordinary integral.
If the function f has a single singularity q between a and b
(a<b),
the Cauchy principal value of its integral from a to b is the limit
(whenever it exists),
as e tends to 0+, of the sum of the integral from
a to q-e
and the integral from q+e to b. Also, if the interval
of integration is ]-¥,+¥[ with a
singularity at ¥ the principal value is the limit,
whenever its exists, of the integral in the interval ]-A,+A[ as A tends to infinity.
When f has a discrete number of singularities between a and b
(a and b excluded, unless both are infinite),
the PV of its integral may be obtained by
splitting the interval [a,b] into a sequence of intervals each containing
a single singularity. The above applies to each of these, and the PV of the integral
over the entire interval is obtained by adding the principal values over all such
subintervals.
The fact that the principal value is used may be indicated by the letters PV
before the integral sign, or by crossing with a small horizontal dash the integral sign
(see illustration above).
However, it is more or less universally understood that the Cauchy principal
value is used whenever needed, and some authors don't bother to insist on this
with special typography.
brentw (Brent Watts of Hickory, NC.
2000-11-21)
How do I solve the differential equation
2(1-x)y" + (1+x)y' + [x - 3 - (x-1)2exp(x)]y = 0
about the pole x=1?
The singularity at x = 1 is a regularFuchsian one
(which means that, if the coefficient
of y" is normalized to 1, then the coefficient of y' has at most a single pole
at x=1 and the coefficient of y has at most a double pole at x=1).
Therefore, the method of Frobenius is applicable.
It consists in finding a solution in the form of a so-called Frobenius series
of the following form (where h=x-x0 in general, and h=x-1 here) with a(0) nonzero:
y = hm [ a(0) + a(1) h + a(2) h2 + a(3) h3 + ... ]
In the above, m is not necessarily an integer, so that a Frobenius series
is more general than either a Taylor series (for which m is a natural integer)
or a Laurent series (for which m is any integer).
In the DE we're asked to study, we have:
-2h y" + (2+h) y' + [h-2-h2exp(1+h)] y = 0
The method of Frobenius is simply to expand the above LHS in terms
of powers of h to obtain a sequence of equations that will successively give
the values of a=a(0), b=a(1), c=a(2), d=a(3), etc.
Let's do it.
The above LHS is hm-1 multiplied by:
We have to successively equate to zero all the square brackets.
Since a is nonzero, the first square bracket gives us the acceptable value(s)
of the index m (this is a general feature of the method and this first
critical equation is called the indicial equation).
Generally, the indicial equation has two roots (for a second-degree DE)
and this gives you a pair of independent solutions.
Usually, when the roots differ by an integral value (like here)
you've got (somewhat) bad news, since the Frobenius method is only guaranteed to
work for the "larger" of the two values of m.
However, "by accident" you're in luck here:
The case m=0 gives b=a (second bracket).
Then, the third bracket gives zero for the coefficient of c
(that's the usual problem you encounter after N steps
when starting with the smaller root, if the two roots differ by N)
but it so happens that the rest of the bracket is zero too!
(That's exceptional!) So you can continue with an arbitrary value of c
and obtain d as a linear combination of a and c using the next bracket
(which I was too lazy to work out, since I knew tough
problems could not occur past that point).
The way to proceed from here is to first use a=1 and c=0 to get the first solution
as a Frobenius series F(h),
then a=0 and c=1 to get a linearly independent solution G(h).
The general solution about the singularity x=1 is then
a F(x-1) + c G(x-1).
(You don't have to bother with the index m=2 in this particular case.)
brentw (Brent Watts of Hickory, NC.
2000-11-21)
Laurent Series
How to determine the Laurent series of a function about a singular point.
For each singular point (or pole) zo,
you want to expand f (zo+h).
If a pole has multiplicity n, then
hnf (zo+h)
is normally an analytic function.
Compute its Taylor expansion about h=0 and divide that series
by hn
to have the Laurent series about that particular pole.
Let's present the computation step-by-step for the following simple example:
f (z) = 1 / [z (z-1)2 ]
Let's examine the double pole at z = 1.
First we compute f (1+h) [in the neighborhood of the pole,
h is small ].
It's just a matter of replacing z by (1+h). Nothing to it:
Multiply this by h2 to obtain an analytic function about
h = 0, namely:
g(h) = h2f (1+h) = 1 / (1+h)
The Taylor expansion of g is well known:
g(h) = 1
- h + h2
- h3 + h4
- h5 + h6
- h7 + ...
Since f (1+h) = g(h)/h2, we divide the above by
h2 to obtain the Laurent expansion
of f (1+h) about h=0 or, equivalently,
of f (z) about z=1 :
f (1+h) = 1/h2 - 1/h + 1
- h + h2
- h3 + h4
- h5 + ...
Usually, we're only concerned with the coefficient of 1/h, which is called the
residue for that pole (here it's equal to -1). The integral of a function
along any closed contour encircling a certain number of poles is equal to
2pi times the sum of the residues for those poles.
This can be a practical way to compute easily many
definite integrals that would otherwise be difficult to obtain. Examples
follow.
Many textbook insist on the following format (which I don't recommend):
It's sometimes desirable to present the function globally
as the sum of so-called simple elements about every pole
and an entire function (which is just a polynomial when
the function is rational,
like this one).
f (z) =
1/(z-1)2 - 1/(z-1) + 1/z + 0
That type of reduction allows the immediate integration
of rational functions:
yourm0mz (
2001-12-15)
How do you find this definite integral?
(I am using the positive x-axis as a branch cut.)
When attempting to apply Cauchy's residue theorem
[the fundamental theorem of complex analysis] to multivalued functions
(like the square root function involved here), it is important to specify
a so-called "cut" in the complex plane were the function is allowed to be discontinuous,
so that it is everywhere else continuous and single-valued.
In the case of the square-root function, it is not possible to give a continuous definition
valid around any path encircling the origin.
Therefore, a so-called "branch-cut" line
must be specified which goes from the origin to infinity.
The usual choice is [indeed] to use the positive x-axis for that purpose.
This choice means that, when the angle q is in
[0,2p[, the "square root" of the complex number
z = r exp(iq) is simply
Öz º Ör exp(iq/2)
(the notation Ör being unambiguous because r is a positive
real number and its square root is thus defined as the only positive
real number of which it is the square).
This definition does present a discontinuity when crossing the positive real axis
(a difficulty avoided only with the introduction of Riemann surfaces,
which are beyond the scope of our current discussion).
With the above definition of the square root of a complex argument,
we may thus apply the Residue Theorem to the function
f(z)=1/(1+z2)Öz on any contour which does not cross the
positive real axis.
We may choose the contour pictured at left, which does not encircle the origin
[this would be a no-no, regardless of the chosen "branch cut"]
but encloses the pole at +i when the outer circle is big enough.
On the outer semicircle, the quantity |f(z)| eventually becomes much smaller
than the reciprocal of the
length of the path of integration.
Therefore, the contribution of the outer semicircle to the
contour integral tends to zero as the radius tends to infinity.
The smaller semicircle is introduced to avoid the singularity at the origin,
but its contribution to the contour integral is infinitely
small when its radius is infinitely small.
What remains, therefore, is the contribution of the two straight parts of the contour.
The integral along the right part is exactly the integral we are asked to compute,
whereas the left part contributes i times that quantity.
All told, the limit of the contour integral is (1+i) times the integral
we seek.
Cauchy's Theorem states that the contour integral equals
2pi times the sum of the residues it encircles.
In this case, there's only one such residue, at the pole i.
The value of the residue at pole i is the limit as h tends to
zero of h f(i+h), namely
1/2iÖi,
so the value of the contour integral is
pÖi = pÖ2(1+i)/2.
As stated above, this is (1+i) times the integral we want.
Therefore, the value of that integral is exactly
p/Ö2,
or about 2.22144146907918312350794049503...
For what values of a does this integral converge?
What's the value of the integral when it converges?
The previous article deals with the special case
a = -1/2.
In general, we see that the integral makes sense in the neighborhood of zero
if a>-1 and it converges in the neighborhood of
+¥ when a<1.
All told, the integral converges when a
is in the open interval ]-1,1[.
We apply the above method to
f(z) = za/(1+z2)
[defining za with the positive x-axis as
branch cut] on the same contour (pictured at right).
The smaller semicircle is useless when a is positive and
it has a vanishing contribution otherwise
(when a>-1).
The contribution of the outer semicircle is vanishingly small also
(when a<1) because
|f(z)| multiplied by the
length of the semicircle becomes vanishingly small when the radius becomes large enough.
On the other hand, the contribution of the entire positive x-axis is the integral
we are after, whereas the negative part of the axis contributes
exp(ipa) as much.
All told therefore, Cauchy's theorem tells us that our integral is
2pi/(1+exp(iap))
times the residue of f at the pole z = i.
The residue at z = i is the limit, as h tends to zero,
of h f(i+h), which is simply
exp(iap/2)/2i.
This makes the integral equal to
p exp(iap/2) / (1+exp(iap))
That boils down to p/(2 cos ap/2)
so that we obtain:
ó õ
¥
xa dx
=
p
[ -1 < a < 1 ]
0
1 + x2
2 cos (ap/2)
We may notice that this final result is an even function of a,
which we could have predicted with the simple change of variable y = 1/x...
(2007-05-08) The Vocabulary of Complex Analysis
Holomorphic functions, entire functions, meromorphic functions, etc.
Holomorphic Functions (analytic functions
of a complex variable)
A complex function f of a complex variable
which is differentiable about every point z of its domain
is called an analytic function,
an holomorphic function,
or a complex differentiable function :
lim
f (z+h) - f (z)
= f ' (z)
h ® 0
h
The existence of such a derivative function
( f ' )
is a much more restrictive condition in the complex realm than
among real numbers, since it implies essentially that f
is differentiable infinitely many times and
possesses a convergent expansion as a Taylor series
about every point x
inside its domain of definition.
f (z) =
¥
å
n = 0
f (n) (x)
(z-x) n
where f (0) = f
n!
f (n+1) =
[ f (n) ]'
We may break down complex quantities
into their real and imaginary parts:
f (z) =
f (x+iy) =
u + i v =
u(x,y) + i v(x,y)
In this, both u and v are real functions of the
two real variables x and y.
The above differentiability of f as a
function of the complex variable x+iy
implies the following equation in terms of the
partial derivatives
of f with respect to the two real variables
x and y.
i ¶f / ¶x
=
¶f / ¶y
In terms of u and v,
this translates into the following differential equations,
known as the Cauchy-Riemann equations,
which are a necessary condition for the related function
f to be holomorphic (note how these equations imply that
both u and v are necessarily differentiable infinitely many times
with respect to x and y as soon as they are known to be differentiable once).
An holomorphic function
defined over the whole complex plane
(without any singularities) is called an entire function.
Liouville's Boundedness Theorem asserts that such a function can only
be bounded if it's constant.
Meromorphic Functions
A meromorphic functionf over some domain D
is an holomorphic function on the domain obtained by removing
from D a discrete set of isolated ordinary poles (as opposed to
essential singularities).
That's to say that a neighborhood of any such singularity x exists
where the function f (z)
multiplied by some power of (z-x) is simply an holomorphic
function (i.e., without singularities).
Etymologically, meros
(meroV = part) is opposed to holos
(holoV = whole).
(2021-06-22) Cauchy-Riemann equations (d'Alembert-Euler conditions)
On the partial derivatives in an analytic function of a complex variable.
These first-order differential relations between the real and imaginary parts
of a complex-valued function f = u+iv of the complex variable z = x+iy
indicate that the mapping which sends (x,y) to (u,v) is conformal
(which is to say that it preserves angles and planar orientation).
This turns out to be a necessry condition for the analyticity of the function f.
The equations were first published in 1752 by
Jean-le-Rond d'Alembert (1717-1783)
in an essay on fluid mechanics.
They were first mentioned as a criterion for analyticity by
Leonhard Euler (1707-1783) in 1777.
Augustin Cauchy (1789-1857) started using them as a cornerstone
for his theory of functions in 1814. They take center stage in the celebrated 1851 dissertation of
Bernhard Riemann (1826-1866).
As advertised above, the existence of a (first) derivative with respect to
a complex variable is a much stronger condition than its counterpart for real variables.
Let's examine more precisely what this entails...
Let f be a differentiable complex function of the
complex variable z.
Let's call u and v the the real and imaginary parts of f
and let's introduces as x and y the real variables which z reduces to:
z = x + i y
f (z) = u(x,y) + i v(x.y)
The differentiability of f about point z says that
the following limit is well-defined as the (complex) quantity h tends to zero.
lim
f (z+h) - f (z)
= f ' (z)
h ® 0
h
This implies, in particular, that the limit exists when h=x is real and when h=iy
is imaginary, which says that both u and v have partial derivatives with respect
to either x or y. Furthermore, the limits for h=x and h=iy as either
x or y tends to zero must be identical (or else, there would not be a
well-defined limit in the neighborhood of h=0) which implies the following:
Cauchy-Riemann Equations
¶u
=
¶v
and
¶v
= -
¶u
¶x
¶y
¶x
¶y
Contrary to Riemann's belief, the converse isn't quite true
as the existence of partial derivatives
satisfying the Cauchy-Riemann equations doesn't imply
that u+iv is differentiable.
A related fact had also escaped Cauchy in 1821 (see
Cauchy's mistake).
One counterexample due to
Carl Johannes Thomae (1870)
is the following function, which meets all conditions but doesn't have a derivative at point zero
(where it's not even continuous):
f (x+iy)
=
sin ( 4 Arctg
x
) when y ¹ 0 (and f = 0 when y = 0)
y
When the partial derivatives are continuous (which isn't the case in the above example)
a theorem due to Clairault (1740) applies, which states that the values of
partial derivatives with respect to several variables do not depend on the order of the differentiations.
Continuity of the partial derivatives isn't required to apply the
Looman-Menchoff theorem
which states that a function known to be continuous with partial derivatives in a
neighborhood of z
is holomorphic in that neighborhood if and only if it satisfies the Cauchy-Riemann equations.
Satisfying the Cauchy-Riemann equations only at point z isn't enough.
(HINT: The continuous function z5/|z|4
isn't analytic anywhere.)
Generalizations of the Looman-Menchoff theorem have been devised,
culminating in the detailed results published in Russian by
Grigorii
Khaimovich Sindalovskii (1928-2020) in 1985:
(2021-06-22) Wirtinger Derivatives = Wirtinger Operators (1926)
Applying the methods of calculus to non-analytic complex functions.
Consider any function w of the two variables x and y.
Let's introduce, as a new pair of variables, z=x+iy and z*=x-iy.
Using partial derivatives:
dw = wx dx + wy dy
= wz dz + wz* dz*
Since dx = ½ (dz + dz*) and dy = ½ (i dz* - i dz) we obtain:
½ wx (dz + dz*) + ½ wy (i dz* - i dz)
= uz dz + uz* dz*
Equating separately the coefficients of dz and dz* yields :
wz = ½ (wx - i wy )
wz* = ½ (wx + i wy )
Let's translate this into the standard del notations for partial derivatives:
Wirtinger Derivatives for a Single Complex Variable
¶
= ½ (
¶
- i
¶
) and
¶
= ½ (
¶
+ i
¶
)
¶z
¶x
¶y
¶z*
¶x
¶y
Because the Wirtinger derivatives are just partial derivatives, they obey the same
standard rules of calculus
as straight derivatives, including linearity, product rule and chain rule.
Interestingly, the condition ¶z* f = 0
is equivalent to the Cauchy-Riemann equations because:
¶z* (u+iv) =
¶x (u+iv) +
i ¶y (u+iv) =
(¶x u
- ¶y v) + i
(¶x v
+ ¶y u)
Thus, loosely speaking, an analytic function depends only on z, not z*.
The first Wirtinger derivative coincides with the ordinary derivative
in the case of analytic functions but it's also defined for non-analytic functions
(whenever partial derivatives exist).
Wirtinger derivatives of some functions
f (z) = f (x+iy)
¶f / ¶z
zn
n zn-1
Analytic f (z)
f ' (z) = df / dz
(z*)n
0
Analytic f (z*)
0
x = Re (z) = ½ (z*+z)
1 / 2
y = Im (z) = ½ (iz*-iz)
-i / 2
|z| = (z z*)½
½ z* / |z|
|z|n
½ n z* |z|n-2
Analytic f (|z|)
½ z* f ' (|z|) / |z|
Log |z|
1 / z
This last example is of particular interest since the
Log function is not well-defined in the complex plane,
but Log |z| is. That real-value function is not analytic anywhere,
but it's harmonic everywhere
(except at the origin).
Complex functions of several complex variables :
The generalization to n complex variables z1 ... zn is straightforward:
Wirtinger Derivatives for Several Complex Variables
(2021-08-09) Cauchy Integral Formula
Fundamental Theorem of Complex Analysis.
If f is holomorphic, in a
simply-connected neighborhood of point a, then its
value at point a is given by an integral around any contour C
encircling a within that neighborhood:
f (a) =
1 2pi
ò
C
f (z) z-a
dz
Differentiate both sides n times with respect to a to obtain a corollary :
f(n) (a) =
n! 2pi
ò
C
f (z) (z-a) n+1
dz
In the plain version stated above, the contour avoids all zeros of f.
In some cases, that requirement is inconvenient
(as we may not know a priori where those zeros are). A zero on the contour
contributes to the integral exactly the half-sum of what it would if it was on either side!
In 1831, Augustin Cauchy (1789-1857)
stated this theorem for holomorphic functions only (no poles).
He extended it to meromorphic functions (poles and zeros) in 1855.
The argument principle is used in the proof of
Rouché's theorem (1862).
Even when the computation of the contour integral is marred
with substantial rounding errors it's easy to
infer the result with absolute accuracy knowing only integers can be involved.
The method has been used to locate nontrivial zeros of the zeta function:
First a rectangular contour is used which spans the full width of the critical strip
(0 < x < 1)
The result is then compared to what's obtained with an infinitesimally narrow central section thereof,
counting all the zeros arbitrarily close to the critical line at x = ½.
(2019-08-23) Riemann Mapping Theorem (1851, Carathéodory 1912)
Existence of a biholomorphic mapping from U to the open unit disk.
A biholomorphic mapping is a
bijectiveholomorphic mapping
whose inverse is also holomophic. Such a mapping between
the open unit disk and a proper part U
of the complex plane is called a Riemmann mapping.
It's necessarily a conformal map
(i.e., it preserves locally the angles of lines and the orientation of surfaces,
but not necessarily their areas).
In his thesis (1851) Bernhard Riemann (1826-1866)
stated that such a mapping exists for any nonempty simply-connected open proper
subset U of .
That statement is now known as the Riemann mapping theorem.
(2021-08-05) Schlicht functions are
univalent functions from the open unit disk to the complex plane,
normalized to f (0) = 0 and f ' (0) = 1.
Any univalent function g reduces to a
schlicht function f using an affine transformation
made legitimate by
the fact that g' (0) ¹ 0 :
f (z) =
g (k z) - g (0) k g' (0)
In this, k > 0 is at most equal to the radius of convergence R of g.
Thus, the radius of convergence of f is at least equal to 1, as required by law.
General properties of univalent functions are often just stated in terms of schlicht functions,
whose radius of convergence is always at least 1:
With a0 = 0 and a1 = 1 ,
f(z) =
¥ å n=0
an zn when | z | < 1
A major fact about schlicht functions was called
Bieberbach's conjecture for 68 years (1916-1984).
It's now known as De Branges's theorem :
| an | ≤ n
This result is sharp, as equality is achieved in the following example...
Key example :
An important family of schlicht functions consists of the rotated Koebe functions
which depend on a complex parameter q of unit norm
(i.e., | q | = 1).
The basic Koebe function is the case q = 1.
fq (z) =
z (1 - q z) 2
=
¥ å n=0
n qn-1 zn
To see that f is injective, consider that f (u) = f (v) implies:
0 =
u (1 - q v) 2
-
v (1 - q u) 2
=
(u - v)
[1 - q2 u v]
If u and v are different, this requires the square bracket to vanish, which is not
possible when u and v are inside the unit disk, since the modulus of
q2 u v is then strictly less than unity.
Injectivity does fail everywhere on the boundary. [HINT: If u
is on the unit circle, so is v = 1/(q2 u).]
This doesn't prevent f from being schlicht,
but makes those functions borderline cases
(| q | < 1 would be less tight).
Robertson's lemma (1936)
The special case p = 2 of the lemma below appears (without proof)
in the 1936 paper where M.I.S. Robertson proposed a new conjecture sufficient
to establish Bieberbach's conjecture, a fact which would be put to
good use by Louis de Branges in his celebrated proof thereof (1984-85).
Lemma :
For a given schlicht function f and any positive integer p,
there is a unique schlicht function
Fp such that:
Fp (z) p = f (z p )
Proof : Let's define Fp using the
binomial theorem for exponent 1/p in a small
enough neighborhood of zero, in the following way:
Fp (z) =
¥ å k=0
b pk+1 z pk+1
= z
¥ å k=0
(
1/p k
)
y k
Where y =
f (z p ) z p
- 1 = z p
¥ å n=2
a n z p(n-2)
The other possible solutions would be deduced from that one by multiplying it into a nontrivial
p-th root of unity, w, but this would make the derivative at
the origin be w ¹ 1, which is ruled out
for a schlicht function.
With the issue of ambiguity so resolved in a neighborhood of zero where the intermediate
(binomial) series converges (because | y | < 1)
the defining algebraic relation between f and F
persists for the latter by analytic continuation to the
b series for as long as the former is defined without singularities, which is the case whenever
| z | < 1.
Thus the radius of convergence of the b series is always at least 1, as required.
It remains only to show that the Fp so defined is injective:
Fp (u) = Fp (v)
implies that the p-th powers of the two sides are equal. which means: f (u p )
= f (v p )
and, since f is injective, u p = v p.
Plug this equality into the b series for Fp to get
Fp (u) / Fp (v)
= v/u, so that the former ratio can only be unity if the latter is.
Apply this result, for any positive integer p, to our previous family parametrized by
q = r exp(i q), with
0 < r ≤ 1,
to obtain a 3-parameter family of schlicht functions (2 continuous parameters and a discrete one):
f(z) =
z (1 -
r e iq z p ) 2
=
¥ å n=0
n r n-1 e i (n-1) q z p (n-1)+1
The basic Koebe function is retrieved for r = 1, q = 0
and p = 1.
(2021-08-08) Starlike
schlicht functions.
(Nevanlinna, 1921)
Bieberbach's conjecture was first proved in this special case.
A holomorphic function is called starlike
when its domain is radially convex
(or star convex) which neans that:
If it contains z, then it also contains t z
for any t in the interval [0,1].

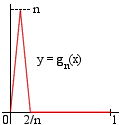 Consider, for example, the sequence of functions gn on [0,1]
for which gn(x) is n2x when x is in [0,1/n],
Consider, for example, the sequence of functions gn on [0,1]
for which gn(x) is n2x when x is in [0,1/n],
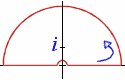 With the above definition of the square root of a complex argument,
we may thus apply the Residue Theorem to the function
With the above definition of the square root of a complex argument,
we may thus apply the Residue Theorem to the function
